![[Lane Detection] Multi-level Domain Adaptation for Lane Detection(CVPR'22) 논문 리뷰](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fcrpyte%2FbtrLPdFsjAI%2FAAAAAAAAAAAAAAAAAAAAAGaiI3Kq9rXIzZlb9OuyBeIeiHvcpC7ExfOUKqXRDPAU%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3Dc2uRsJIaPO8phRCZ073eUsuCbgQ%253D)
반응형
오늘은 Lane Detection을 Domain Adaptation으로 푸는 MLDA(CVPR'22) paper에 대한 논문 리뷰 포스팅을 하려고 한다! Domain Adaptation과 Lane Detection의 조합이라니.. 신선하다 🌿
Title
Multi-level Domain Adaptation for Lane Detection (CVPR'22) - CULane <-> TUSimple dataset에 대해 cross evaluation을 진행하고, 두 데이터셋 사이의 domain shift를 지적
- Lane Detection에서 domain shift 문제를 지적한
(거의 첫번째)논문 - 이 논문은 대체 어떤 부분에서 lane detection 데이터셋간 domain shift가 발생한다고 생각하고, 이를 어떻게 해결하려고 하는가?
Motivations
- Lane detection 모델은 source domain과 target domain이 다르면 드라마틱한 성능 하락이 발생하고(domain shift), 이를 위해 re-labeling이나 re-training을 할 수 있겠지만 비용이 많이 든다.
- 따라서 위 domain shift를 **기존의 UDA(Unsupervised Domain Adaptation) 모델**로 해결하려고 했지만, 다음과 같은 이유로 lane detection에 바로 적용이 불가했다.
- lane과 background class는 비율의 imbalance가 존재하고, 이는 self-training 과정에서 lane이 high-entropy를 가지지만 무시되는 원인이 된다.
- 기존 UDA의 pixel-wise loss function은 lane의 모양과 위치의 특징을 포착하지 못한다.
- ✅ 따로 왜 두 데이터셋간 domain shift가 발생하는지에 대한 분석은 paper에 없다.

Methodology
- 배경과 차선의 confidence를 balancing 하고, 차선의 모양과 위치에 집중하기 위해 다음과 같은 3가지 part의 모델을 제시한다.

[1] Pixel-level : Self-training with confidence constraints
Motivation
- Self-training의 framework를 사용하고 싶지만, 다음과 같은 문제가 발생했다.
- Lane이 이미지에서 차지하는 픽셀 비율은 매우 적고, target domain과 lane의 위치는 다르다. 그에 반면 background의 경우 안정적이고, adaptation도 쉽다.
- 위 특성은 배경과 차선의 imbalanced distribution(confidence imbalance)을 야기하고, self-training 과정에서 pseudo label을 생성할 때 배경에 너무 dominant 되는 문제가 발생한다.
Confidence constraint

- Pseudo label을 생성할 때 배경과 차선 class의 intrinsic distribution을 동일하게 인식하도록 하기 위함이다.
- Target domain image에 대한 pseudo label 생성 시 픽셀별 일종의 probability gate를 만들어 confidence imbalance를 완화해 더 정확한 pseudo label을 만들 수 있도록 한다.
- 배경과 차선에 대해 각각 alpha threshold를 다르게 설정하여 high-quality의 pseudo label을 효율적으로 생성하도록 한다.
- 위와 같이 생성된 target domain에 대한 pseudo label로 다음과 같은 pixel-wise cross entropy를 이용해 network weight를 업데이트한다. 아래는 해당 loss이다.

[2] Instance-level : Triplet learning with edge pooling
Motivation
- Pixel-wise feature distribution은 source/target domain별로 다르며, 이는 class prediction에 혼동을 줄 수 있다.
- 차선 instance 픽셀 사이의 semantic context는 target domain에서 재구성하기 어렵다.
Triplet learning
- Target domain의 feature를 refinement하기 위해 triplet loss를 사용
- Triplet 구성
- Anchor / Positive examples : masked features of a lane instance in non-background(=4 lanes) class
- Negative examples : features of line detected in background class
- Positive samples와 다른 Negative samples를 만들기 : Canny edge detector로 driving area를 찾고, 여기서 Probabilistic hough transform을 이용해 line을 추출
- 그리고 다음과 같은 Triplet loss를 이용한다.

Edge pooling
- Positive example은 target domain에서 gt가 아니라 pseudo label로 생성되므로, low-quality하다.
- 따라서 상하좌우로 lane area를 확장해줌
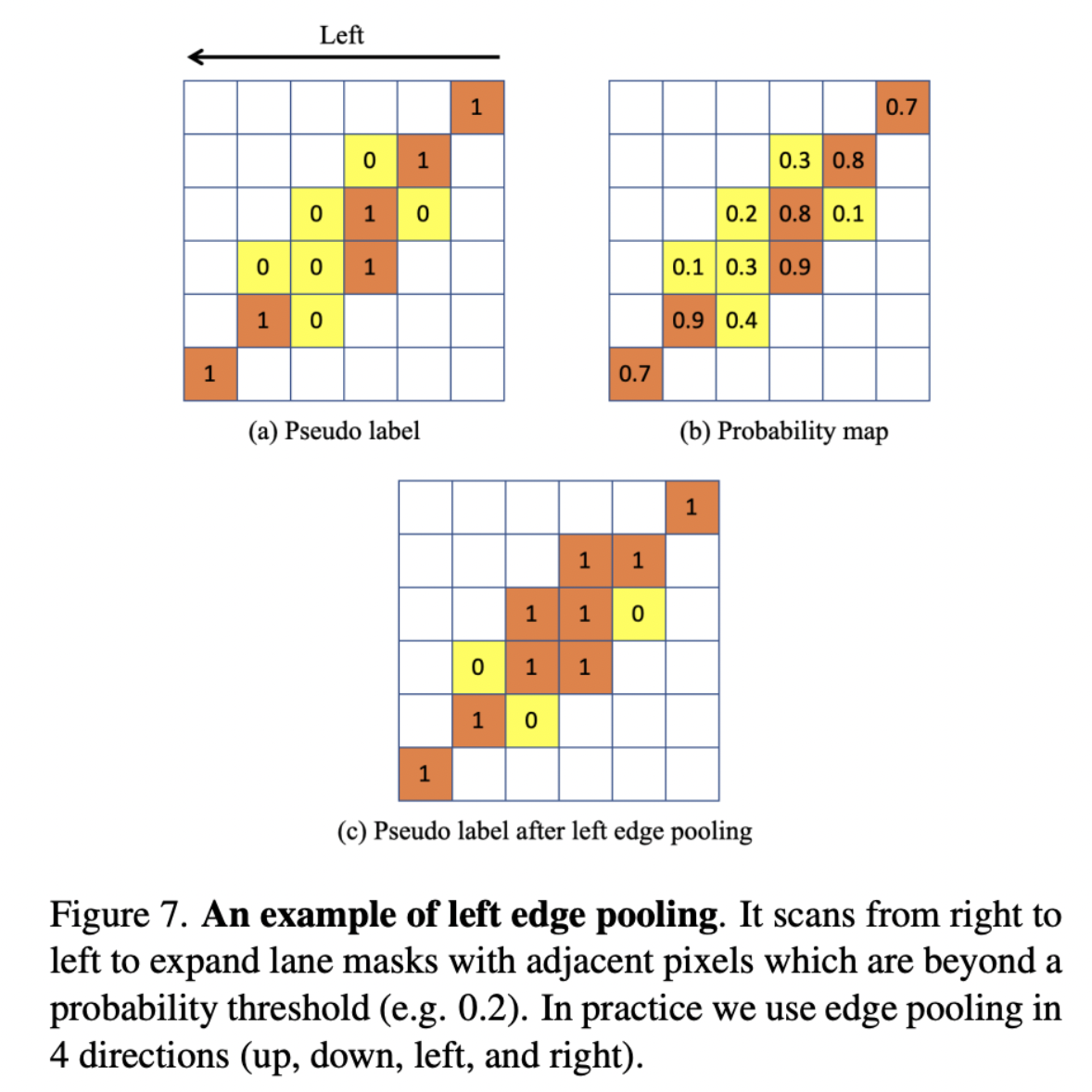
[3] Category-level : Adaptive inter-domain embedding

- Channel과 spatial attention이 들어간 임베딩 모듈을 카테고리별로 사용
- 따라서 위 세가지 method를 합친 final loss는 다음과 같음. (linear sum)

Experiments
[1] Implementation Details
- CULane <-> TUSimple 에 대해 교차로 train/evaluation 진행
- 모든 이미지는 768 * 256으로 resize 하였고, 1-degree rotation augmentation만 사용
- ERFNet 이라는 segmentation model을 모든 DA 모델의 backbone으로 사용함
[2] Results

반응형