![[Daily] MM-EUREKA: Exploring Visual Aha Moment with Rule-Based Large-Scale Reinforcement Learning](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FVSEBv%2FbtsMGOMwnxN%2FAAAAAAAAAAAAAAAAAAAAANF87OdtEEV2uU93XtMlC_In_c6jH0x1DDXUhbr7YNW9%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3D5sraJOScjv%252BrtLGB1mSTNhCEohM%253D)
반응형
TLDR;
- DeepSeek-R1 (rule-based reinforcement learning) 을 Multimodal setting에서 재현한 첫 opensource model
- Multimodal reasoning model 'MM-Eureka'를 제안
Motivation
- DeepSeek-R1을 multimodal setting에서 재현하려는 노력은 많이 있어왔지만, 거의 close source 모델이거나 'aha moment'에서 재현이 잘 안됨
- 여기서 aha moment란 reasoning 중간에 이미지를 다시 체크하거나.. 확인하는 것

Method
- Basic setting: InternVL2.5 (8B, 32B)를 이용 + DeepSeekR1의 rule-based reward를 사용함
- Data clearning: GeoQA 같은 오픈소스 데이터셋을 filtering 해서 사용 (이 과정이 중요했다고 함)

Reward function (rule-based reward)
- DeepSeek R1에서 제안한 accuracy reward와 format reward를 그대로 사용 (두개를 합침)
- Accuracy reward: math-verify library로 answer를 추출해 맞으면 1, 틀리면 0
- Format reward: ...... 이 format 을 맞추면 1, 아니면 0
- $r = r_{acc} + \lambda r_{format}$
Advantage estimation + Policy update
- REINFORCEMENT Leave-One-Out (RLOO) 알고리즘을 사용 (GRPO와 달리 critic model이 필요 없다고 한다)
- K개의 query-response pair를 생성해 advantage estimator를 계산
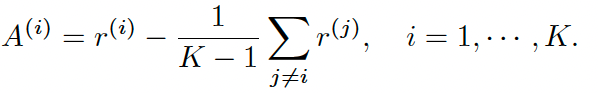
- Actor loss로는 PPO-clip loss를 그대로 사용

- Policy와 reference policy 사이의 KL divergence loss의 경우 GRPO와 같은 method를 사용해 PPO 뒤에 붙임

Result

반응형