![[Daily] VideoChat-R1: Enhancing Spatio-TemporalPerception via Reinforcement Fine-Tuning](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcRrup2%2FbtsNgqkbAuG%2FAAAAAAAAAAAAAAAAAAAAAD94Ux05UnobV1nYGFCAEgkwNchMKf5nuBvTXgCIKiws%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DszTgJd6YY6cnT8U4lLRVT81eFho%253D)
반응형
TLDR;
- VideoLLM에 GRPO를 적용한 또 다른 버전, spatio-temporal perception 성능을 높이고자 했다고 한다.
- VideoLLM의 general capability를 유지하면서 task-specific performance를 높일 수 있다고 함.
Motivation
- Video understanding에는 reasoning ability를 위한 training/evaluation corpus가 부족 + underexplored
Method
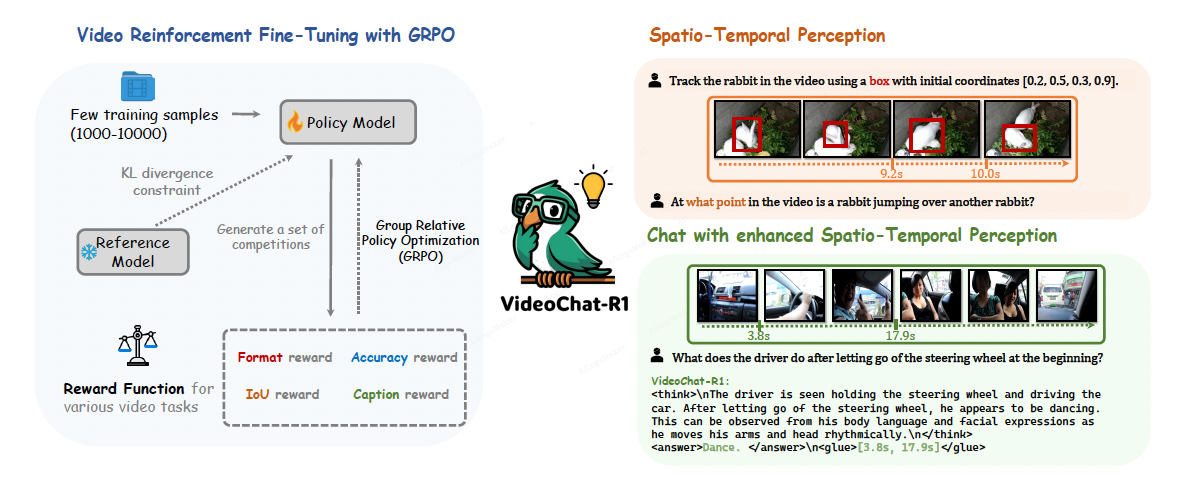
1. GRPO
- PPO에서 critic model에 대한 dependency를 줄인 것
- Response에 대한 group을 생성한 뒤 (여러개 response candidate) 아래와 같이 quality 측정
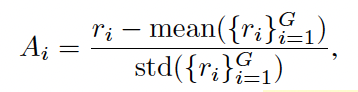
- GRPO는 그룹 내 better answer가 나오기를 encourage한다. Final training objective는 아래와 같음.
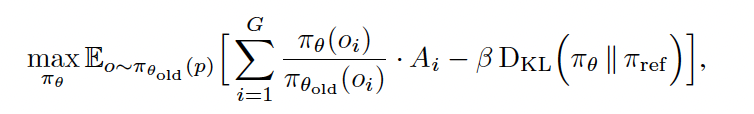
2. Spatio-Temporal Reward of VideoLLM in GRPO
Video understanding task마다 서로 다른 reward 사용 (reward 정의가 생각보다 간단하다)
- Format reward: 각 task마다 format reward를 설정하고 만족하면 1, 아니면 0

2. IoU reward
- Temporal grounding/tracking의 경우 time interval을 요구하는데, gt와 pred의 IoU를 계산해 reward로 사용
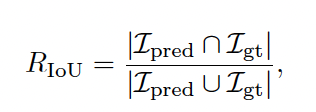
- Accuracy reward in classification
- Multi-choice QA의 경우 정답이 맞으면 1, 아니면 0
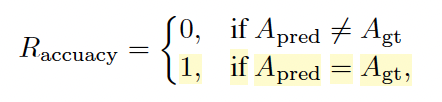
- Recall reward in video captioning
- Key event를 추출하고 gt와 비교해 LLM에게 captioning을 judge 하도록 함
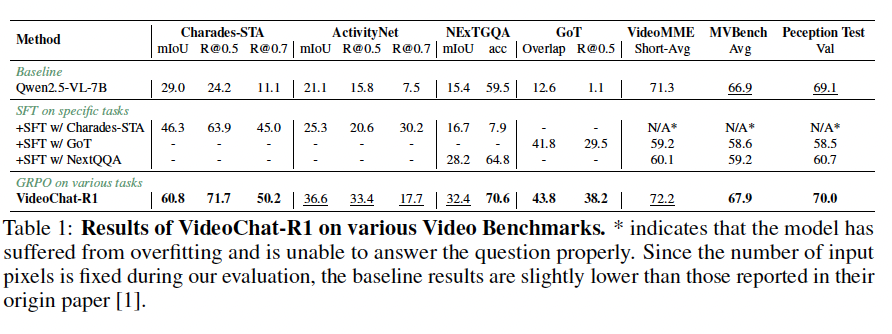
Results
- Base model: Qwen2.5-VL-7B
- Temporal grounding/tracking 등의 task에서 test
반응형
'Computer Vision💖 > Video' 카테고리의 다른 글
| [Daily] Video-R1: Reinforcing Video Reasoning in MLLMs (0) | 2025.04.09 |
|---|---|
| [Daily] Token-Efficient Long Video Understanding for Multimodal LLMs (0) | 2025.03.17 |
| [TIL] Video Diffusion Model과 시뮬레이터 (0) | 2024.09.20 |
| [TIL] Long Video Understanding (0) | 2024.09.06 |