![[Daily] CLIMB: CLustering-based Iterative Data Mixture Bootstrapping for Language Model Pre-training](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FciYCfJ%2FbtsNrznq5jt%2FAAAAAAAAAAAAAAAAAAAAACOs_s8tSkNQCOI2rgY0IOhtMmoBwcgaaNqhOKXlg96_%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DVOPJ%252FrW%252BpAxBURTRXdoL1Sbf4mM%253D)
반응형
지금 하고있는 연구랑 비슷해서 좀 자세히 읽어봤당 역시 OOD 재밌다
TLDR;
- Web data는 보통 web에서 수집되기 때문에 explicit domain label이 없는데, domain-specific training을 위해 optimal pre-training data mixture를 identify하는건 어려운 문제임.
- Cluster-based로 최적의 data mixture weight를 도출하는 framework -> Efficient domain-specific pre-training
Motivation
- Domain-specific task의 성능을 올리는데는 final pre-training phase가 중요하다고 함.
- General/ domain-specific task에 맞는 pre-training data mixture를 도출하는건 어려운 문제임.
- 예를 들어 coding task를 푸는데는 mathematics, reasoning, and security 등의 complementary knowledge가 쓰일 수 있다.

Method
- Efficient domain-specific training을 가능하게 하는 data mixture optimization 방법 제안
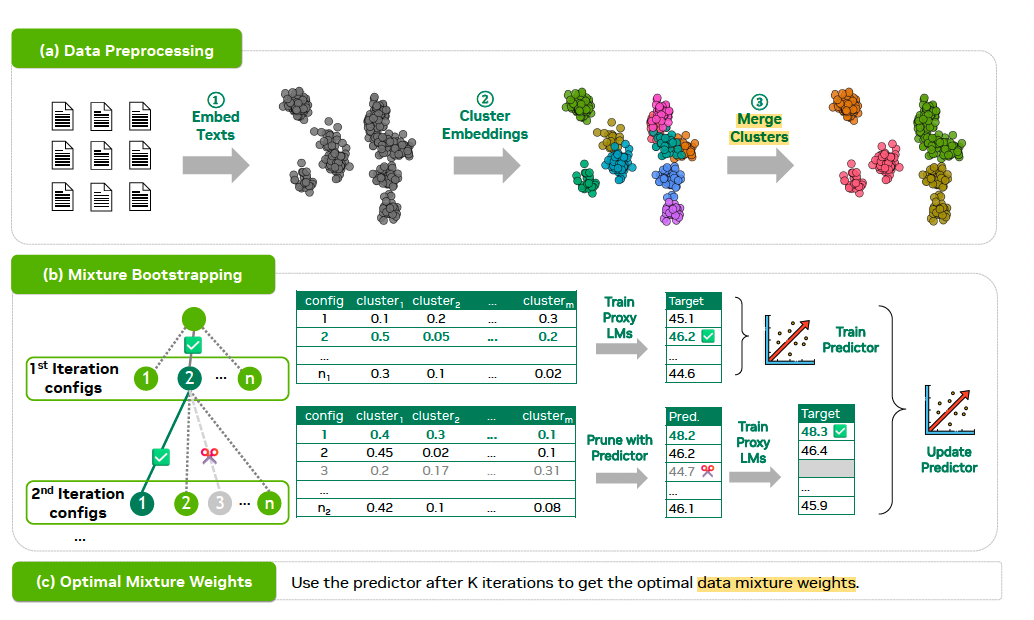
1. Clustering
- 각 raw dataset에 대해 embedding model로 text embedding을 추출한 뒤, kmeans로 clustering
- Pruning: low-quality cluster를 지움
- Merge: 유클리디안 거리 기반으로 similar한 cluster를 merge
2. Iterative Bootstrapping: Mixture Weight Search
- Sampling mixture weight (domain-specific cluster를 어떻게 섞을까 인 것 같음)를 optimize 하기 위한 과정

- Bi-level optimization problem으로 푼다
- 궁극적으론 task performance를 최대화 하는 mixture weight $\alpha$를 구하는 것
- 근데 이렇게 모든 alpha configuration을 시도해서 task performance를 보기엔 학습을 일일이 다 해야해서 너무 time-consuming 함
- 따라서 task performance를 approximate 할 수 있는 proxy model을 학습시킨다.
- 이 proxy model은 아무 regression model이나 가능하다.
- 결국 이 proxy model을 이용해 특정 configuration의 performance를 approximate 한 후 task performance를 maximize하는 적절한 alpha (weight 조합)을 찾는게 목표이다.

- Iterative하게 bootstrap 한다
- 랜덤으로 initialize한 주어진 configuration 중에서 성능이 가장 높은 top N을 고르고, 이를 이용해 predictor를 학습해 alpha를 도출한다. 이 과정을 반복함. (Iteration)

Experiments
- Domain specific한 밴치마크와 general한 밴치마크에서 모두 좋은 성능을 보인다.

- Weight analysis -> iteration을 거듭할수록 weight이 modify 된다.

반응형
'Computer Vision💖 > Domain (DA & DG)' 카테고리의 다른 글
| [CV] Self-training에 대한 간단한 설명 - 가짜 라벨을 학습에 이용하기 (0) | 2022.09.02 |
|---|---|
| [CV] Test-Time Domain Adaptation의 의미와 간단 정리 (0) | 2022.05.08 |
| [DG] Deep CORAL(CORelation ALignment, 2016) 논문리뷰 (0) | 2021.08.27 |
| [DG] Domain Generalization의 대표 알고리즘을 DomainBed로 알아보자 (+ Code) (0) | 2021.08.06 |