![[자료구조] (1) - 연결리스트(Linked List) with Python](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FtclZ8%2FbtqZTUzsxU0%2FAAAAAAAAAAAAAAAAAAAAAGdIBhFAVh2qR8qF8_lyQ2P9n9rL1cEVUs3BSSXRD2Ov%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DvsJDEFZT13NlgGYgIjwp11CRpVY%253D)

연결리스트는 대표적인 추상적 자료구조(Abstract Data Structures) 중 하나이다.
본 게시글은 Python 코드로 작성되었습니다.
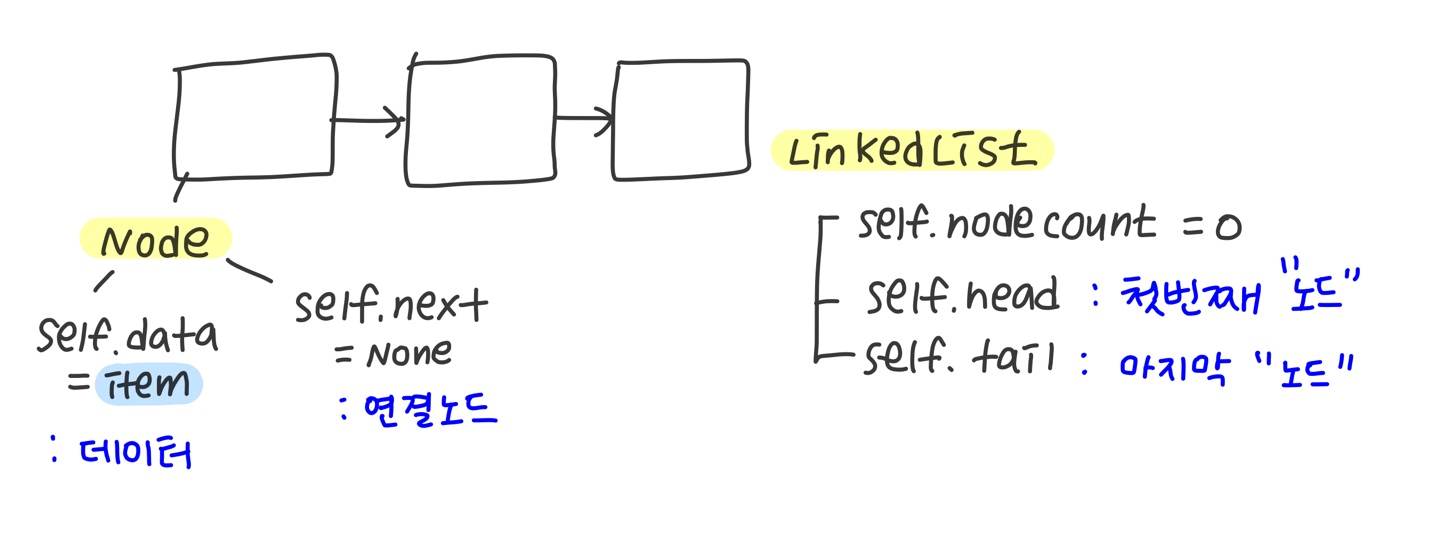
1. 단순 연결리스트의 기본 구조

각 연결리스트는 Node로 구성되어있고, Node안에는 data와 link로 구성되어있다.
안에 들어있는 data는 그림에 나와있는 정수형 말고도 문자, 레코드 등 여러 구조가 가능하다.
Node를 코드로 구성해보면 다음과 같다!
class Node:
def __init__(self, item):
self.data = item # data
self.next = None # next link (다음 인자를 가리킴)
여기서 next는 다음 노드에 접근하는 방법이다.
예시 ) L.head == a
a.next == b
b.next == c
또한, 연결리스트에서 중요한 속성은 크게 셋으로 나뉜다.
✔ Head
✔ Tail
✔ Number of Nodes
class LinkedList:
def __init__(self):
self.nodeCount = 0
self.head = None
self.tail = None
2. 연결리스트의 연산 정의
연결리스트의 연산은 크게 특정 원소 참조, 순회, 원소 삽입, 삭제, 연결이 있다.
1) 특정 원소를 참조할 때
pos번째의 node를 가리키고 싶을 때 쓰는 매서드이다.
def getAt(set, pos):
if pos <= 0 or pos > self.nodeCOunt:
return None # 특정 경우 예외
i = 1
curr = self.head # 연결리스트의 첫번째 노드
# 앞에서부터 하나하나 탐색하기 때문에 선형탐색과 유사
while i<pos:
curr = curr.next
i += 1
return curr단, pos의 예외 범위를 if 로 지정해줘야한다!
2. 리스트를 순회할 때
연결리스트에 들어있는 data를 리스트의 요소로 하나하나 append하고, 최종 리스트를 반환한다.
주의해야할 점은, 리스트 안에 append 되어야 할 것이 node 자체가 아니라 node 안의 data라는 것이다!
def traverse(self):
t_list = []
curr_node = self.head # 첫 노드에 접근
while curr_node != None: # tail이 되면 none이 됨
t_list.append(curr_node.data) # 노드가 아니라 item을 넣음
curr_node = curr_node.next # 다음 노드에 접근
return t_list
3. 원소 삽입
연결리스트의 pos 위치에 원소를 삽입하는 기본 코드는 다음과 같다.
마지막에 nodeCount는 1을 더해준다!
def insertAt(self, pos, newNode):
prev = self.getAt(pos-1) # pos 이전의 노드를 prev로 설정
newNode.next = prev.next
prev.next = nextNode
self.nodeCount += 1 근데 이 코드에서 예외 처리가 필요하다. 이 코드는 삽입 위치가 맨 앞, 맨 끝일때를 처리하지 못한다.
그래서 head와 tail을 따로 조정해주는 코드가 필요하다!
def insertAt(self, pos, newNode):
# pos 예외 범위 지정
if pos<1 or pos>self.nodeCount:
return False
# 리스트 맨 앞 삽입할 때
if pos==1:
newNode.next = self.head # 기존 head가 newNode의 next로 밀려남
self.head = newNode
else:
prev = self.getAt(pos-1) # pos 이전의 노드를 prev로 설정
newNode.next = prev.next
prev.next = nextNode
# 리스트 맨 뒤 삽입할 때
if pos==self.nodeCount +1:
self.tail = newNode
self.nodeCount += 1
return True하지만 여기서 tail을 찾으려면 앞에서부터 차근차근 찾아야한다.
그럼 선형 배열과 비슷한 복잡도가 발생하므로, 비효율적일 수 있다!
따라서 다음과같이 코드를 수정해볼 수 있다.
def insertAt(self, pos, newNode):
if pos<1 or pos>self.nodeCount:
return False
if pos==1:
newNode.next = self.head
self.head = newNode
# prev를 미리 지정
else:
if pos == self.nodeCount +1:
prev = self.tail
else:
prev = self.getAt(pos-1)
newNode.next = prev.next
prev.next = newNode
if pos == self.nodeCount + 1:
self.tail = newNode
self.nodeCount += 1
return True이전 코드의 else: 부분을 tail일때와 tail이 아닐때로 나누어 tail연산이 구분되어 일어나도록 한다.
이때 연결리스트의 원소 삽입 복잡도는 다음과 같다.
- 맨 앞 삽입 : O(1)
- 중간 삽입 : O(n)
- 맨 끝 삽입 : O(1) (tail 포인터 때문)
4. 원소 삭제
pos위치에서 pop을 하면, 그 데이터를 리턴하게 한다.

기본 코드는 다음과 같다.
def popAt(self, pos):
if pos<1 or pos>self.nodeCount:
raise IndexError
curr = self.getAt(pos) # 제거할 node
prev = self.getAt(pos-1) # 이전 node
prev.next = self.getAt(pos+1)
self.nodeCount -=1
return curr.data하지만 이 코드에도 예외 처리를 해줘야한다.
역시 맨 앞, 맨 뒤를 제거할 때, 유일한 리스트 원소를 제거할 때를 처리하지 못하므로 다시 코딩을 해준다!
def popAt(self, pos):
if pos<1 or pos>self.nodeCount:
raise IndexError
curr = self.getAt(pos) # 제거할 노드
if self.nodeCount == 1 & pos == 1: # 유일한 리스트
self.head = None
self.tail = None
elif pos == 1: # 유일하지 않지만 맨 앞 삭제
self.head = self.getAt(pos+1)
else:
prev = self.getAt(pos-1)
if self.nodeCount != pos: # 맨 뒤가 아닐 때
prev.next = self.getAt(pos+1)
else: # 맨 뒤 삭제
self.tail = prev
prev.next = None
self.nodeCount -= 1
return curr.data
5. 두 리스트 연결
# L : 이어붙일 리스트
def concat(self, L):
self.tail.next = L.head # 원래 리스트의 맨 끝이 이어붙일 리스트의 처음
# L에 주어진 리스트가 빈 리스트일 때 예외처리
if L.tail:
self.tail = L.tail # 내 원래 tail을 이어붙인 리스트의 tail로 가게함
self.nodeCount += L.nodeCount # count는 두개를 합한 만큼
'Algorithms 💻 > Basic' 카테고리의 다른 글
| [알고리즘] 백트래킹(Backtracking)을 알아보자 (0) | 2022.04.05 |
|---|---|
| [알고리즘] 특정 기준으로 리스트 정렬하기 (python) - key=lambda (0) | 2022.03.27 |
| [코테] 자주 쓰이는 Python 기본 함수 정리 (계속 업데이트) (2) | 2022.03.26 |
| [알고리즘] 큐를 이용해 BFS 구현하기 (python) (0) | 2022.03.21 |
| [자료구조] - (2) 스택(Stacks) with Python (0) | 2021.03.11 |