![[PyTorch] PyTorch Autograd 이젠 공부하자 - pytorch.autograd 총정리하기 (+code)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F9LL8K%2FbtrtlURRlns%2FAAAAAAAAAAAAAAAAAAAAAH9kbjMFbLxkNshAMDKXckGXIBD7Qp56GSD_bd3eACHd%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1761922799%26allow_ip%3D%26allow_referer%3D%26signature%3DLy8TpeRCYdvZGocKzykOnCunN1E%253D)

오늘은 평소 간과하고 넘어갔던 Pytorch의 Autograd에 대해 포스팅해보려고 합니다. 최근 backward 함수를 변형해야할 일이 있어서 여러가지를 시도해보다가 제가 정작 PyTorch를 잘 모르고 있다는 사실을 깨달아 버렸네요..ㅎㅎ !! Autograd를 이해하기 위한Background 부터 차근차근 정리해보도록 하겠습니다. :)
Background
# 순전파와 역전파
우리가 아는 신경망(Neural Network)은 흔히 순전파(Forward propagation)와 역전파(Backward Propagation)으로 나뉩니다. 각각의 역할은 다음과 같이 요약할 수 있겠습니다.
- 순전파(Forward Propagation) : 모델이 input을 받아 prediction을 생산하는 부분
- 역전파(Backward Propagation) : loss의 gradient(변화도)를 계산해 gradient descent(경사하강법)으로 매개변수(parameter)들을 최적화하는 부분
이러한 두 부분은 각각 pytorch에서 forward 와 backward 함수로 구현됩니다. forward와 backward 부분을 커스텀할 수도 있고, 각각의 부분을 통해 신경망을 완성해 나가는 것이죠.
# 연산 그래프 (Computational Graph)
다음으로는 연산 그래프 구조에 대해 소개하겠습니다. 오늘 소개할 torch의 autograd는 실행된 모든 연산들을 DAG(Directed Acyclic Graph, 방향이 존재하는 순환되지 않는 그래프)에 저장하는 특성을 가집니다. 전형적인 node(노드)와 edge(엣지)를 가지는 graph 형태로 실행 과정이 저장된다는 뜻인데요.
여기서 DAG의 잎(leave)은 input이고, 뿌리(root)는 output 텐서라고 생각하시면 됩니다. 그리고 이 그래프를 뿌리부터 잎까지 추적하며 chain rule을 적용하면 gradient descent 과정이라고 할 수 있겠죠.
예를 들어 $a$와 $b$를 weight(매개변수, 파라미터) 로 갖는 NN에서 loss를 $Q = 3a^3 - b^2$ 라고 가정해봅시다. 여기서 gradient descent 과정을 구현하기 위해서는 다음과 같은 매개변수에 대한 미분값을 구해야 하는 상황일 것입니다.

이렇게 구한 gradient로 경사하강법을 이용해 우리는 매개변수를 업데이트 하는데요, 이러한 일련의 과정을 앞서 언급한 DAG로 나타내면 다음과 같이 나타내집니다. (공식 문서의 그림을 참고해 제가 다시 그렸습니다)
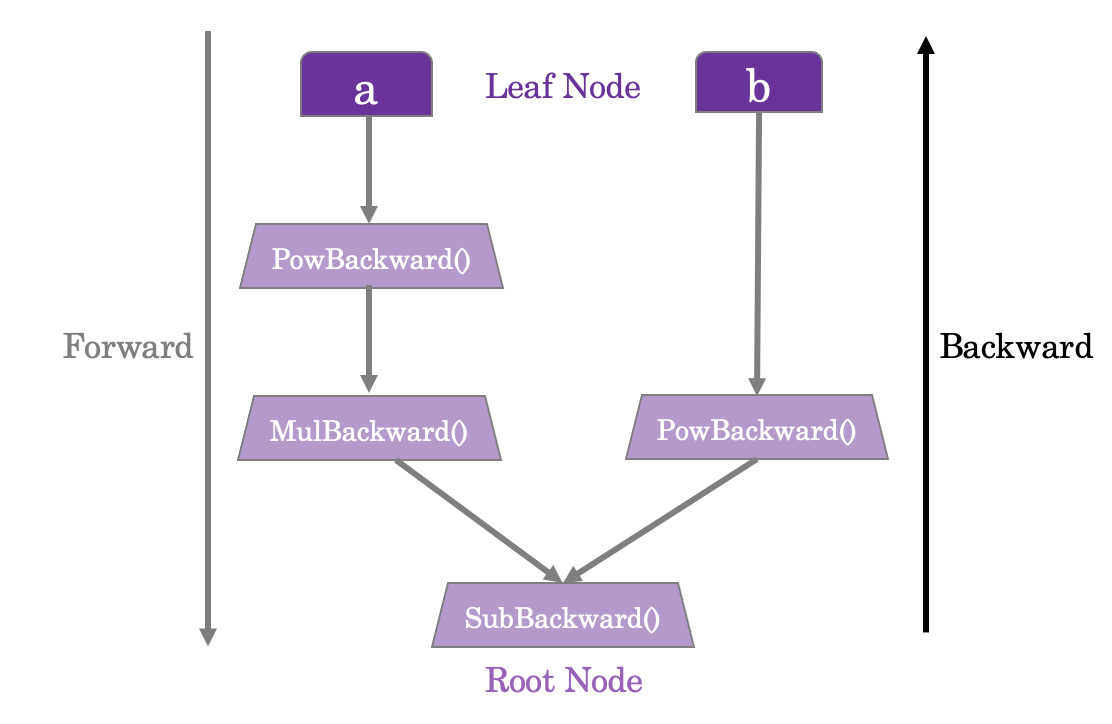
주의해야할 점은 이러한 DAG가 학습할 때마다 처음부터 다시 생성된다는 것입니다. autograd 함수가 호출된 때마다 매번 이러한 DAG 그래프의 모양과 크기, 연산 등이 변경됩니다.
torch.autograd 사용하기
torch.autograd는 위에서 소개한 일련의 역전파 과정을 순조롭게 해주는자동 미분 pytorch 기능입니다. 앞서 소개한 순전파 단계는 .forward() 함수로, 역전파 단계는 .backward() 함수로 구현됩니다. 예시로 이러한 모듈이 어떻게 사용될 수 있는지 알아보겠습니다.
# Toy example
만약 앞선 자동 미분 기능이 없다면 우리는 하나하나 파라미터에 대한 gradient를 직접 구해 다음과 같이 경사하강법을 수행했어야 할 것입니다. 아래는 autograd 기능을 사용하지 않았을 때 경사하강법을 수행하는 모습을 보여줍니다.
# a, b, c, d 4개의 매개변수가 존재하는 상황
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# 다음과 같은 loss 가정
loss = (y_pred - y).pow(2).sum().item()
# 각 파라미터에 대한 gradient 계산 (각각 이루어지는 모습)
grad_y_pred = 2.0 * (y_pred - y)
grad_a = grad_y_pred.sum()
grad_b = (grad_y_pred * x).sum()
grad_c = (grad_y_pred * x ** 2).sum()
grad_d = (grad_y_pred * x ** 3).sum()
# 앞서 구한 gradient를 통해 매개변수 갱신 (경사하강법)
a -= learning_rate * grad_a
b -= learning_rate * grad_b
c -= learning_rate * grad_c
d -= learning_rate * grad_d위의 과정은 autograd를 사용해 이와 같이 간단하게 바뀔 수 있습니다.
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# 앞선 예시와 동일한 loss
loss = (y_pred - y).pow(2).sum()
# autograd의 backward() 함수 활용
loss.backward()
# 앞선 backward 함수로 파라미터별 .grad 속성이 저장되고, 이를 이용해 경사하강법 수행
with torch.no_grad():
a -= learning_rate * a.grad
b -= learning_rate * b.grad
c -= learning_rate * c.grad
d -= learning_rate * d.grad
# Pretrain model과 autograd 이용
이제는 흔히 볼 수 있는 pytorch의 예시인 pretrain 모델을 불러와 모델을 build 하는 과정을 소개하겠습니다. torchvision의 resnet 모델을 불러와서 경사하강법을 수행하는 과정은 다음과 같습니다.
우선 resnet을 불러오고, esnet의 input에 맞는 가상 데이터셋을 랜덤으로 생성하겠습니다.
import torch, torchvision
model = torchvision.models.resnet18(pretrained=True)
# 랜덤으로 데이터와 라벨을 생성합니다.
data = torch.rand(1, 3, 64, 64) # resnet에 맞는 차원으로 생성하기
labels = torch.rand(1, 1000)다음은 순전파 단계입니다. pytorch에서 순전파 단계는 다음과 같이 모델이 prediction을 리턴하는 단계입니다. 따라서 아래와 같이 구현됩니다.
# 순전파 단계
prediction = model(data)마지막으로 역전파와 경사하강법을 수행하는 단계입니다. 우선 loss를 계산한 후, 이를 backward() autograd 함수를 이용해 역전파를 수행해줍니다. 그리고 optimizer를 정의해 .step() 으로 경사하강법을 수행해줄 수 있습니다.
# 역전파 단계
loss = (prediction - labels).sum() # loss 계산
loss.backward()
optim = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9)
optim.step() # 경사하강법(gradient descent)
# Gradient 계산에서 제외하기
모델링을 하다보면 autograd 연산에서 자동으로 gradient가 계산되는 것을 방지하고 싶을 때가 있습니다. 이때는 앞서 소개한 autograd모듈의 자료형인 DAG에서 이러한 파라미터(매개변수)를 제외시켜주면 되는데요, 이때 설정해주는 옵션이 requires_grad=False 입니다. 만약 pretrain 모델의 파라미터는 고정시키고, 파인튜닝(finetuning) 하고자 할 때 이를 다음과 같이 사용할 수 있습니다.
from torch import nn, optim
# pretrain 모델 불러오기
model = torchvision.models.resnet18(pretrained=True)
# resnet의 파라미터가 학습되지 않도록 requires_grad=False로 고정하기
for param in model.parameters():
param.requires_grad = False
# 파인튜닝을 위해 마지막 linear 레이어 추가하기
model.fc = nn.Linear(512, 10)이러한 상황에서 gradient가 계산되는 파라미터는 마지막에 파인튜닝을 위해 추가된 Linear layer의 파라미터가 됩니다. 따라서 옵티마이저 또한 이러한 마지막 레이어의 파라미터를 최적화하기 위해 작동하게됩니다.
References
[0] https://tutorials.pytorch.kr/beginner/blitz/autograd_tutorial.html
[1] https://tutorials.pytorch.kr/beginner/pytorch_with_examples.html
'PyTorch👩🏻💻' 카테고리의 다른 글
| [PyTorch] Multi-GPU 사용하기 (torch.distributed.launch) (0) | 2022.06.10 |
|---|---|
| [TIL] OpenPCDet 가상환경 세팅하기 (cuda11.1 + spconv) (1) | 2022.06.10 |
| [PyTorch] torch-sparse, torch-scatter, torch-geometric 패키지 install 하기 + 오류 해결 방법 (0) | 2022.04.30 |
| [PyTorch] CUDA 11.2 + RTX3090에 맞는 torch version 세팅하기 (3) | 2022.01.30 |
| [PyTorch] torchvision model들의 input channel 변경이 안될 때 (0) | 2021.08.08 |