![[Seg] 간단히 알아보는 Segmentation, Segmentation map](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fc6MrxR%2FbtrFZEwcTHj%2FAAAAAAAAAAAAAAAAAAAAACmBgn7TmGBOv5X6t2YJSGEYWkBWJ-AeR7FALWG-JsZl%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DpI%252FMvX%252BdobC46UQnxE9KKjz16p0%253D)
오늘은 간단히 Sementic Segmentation에 대해 포스팅해보려고 한다! 아래에 해당되는 독자분들이라면 본 게시글이 도움이 될 수 있겠다. 😉🤖 그럼 차근차근 시작해보자.
예상 독자
1. 컴퓨터 비전의 Segmentation에 대한 이해가 처음이신분
# Segmentation 이란?
우선 컴퓨터비전에서 Segmentation이란 image의 픽셀별로 모든 레이블을 예측하는 분야이다. 보통 classification이나 detection의 경우에는 픽셀 단위로 무언가를 예측하지는 않는다. (최종 예측을 위해 픽셀 단위의 정보를 이용할 뿐이다!) 하지만 Segmentation은 이들과 다르게 조금 더 픽셀 단위의 세밀한 예측을 진행한다. 아래 사진을 보자.

위 사진에서 오른쪽을 보면, 픽셀별로 라벨이 매겨져 있는 것을 확인할 수 있다. 사람이 있는 픽셀 부분은 1(사람)이라고 픽셀에 라벨을 붙이고, 풀이 있는 픽셀 부분은 3(풀)에 해당하는 라벨을 붙인다. 따라서 조금 더 세밀하게 예측을 진행하는 task라고 이해하면 되겠다.
# Segmentation의 종류
일단 컴퓨터비전 분야에서 Segmentation에는 크게 Semantic Segmentation과 Instance Segmentation이 있다. 각각의 특징과 정의는 아래 그림을 보면 바로 짐작할 수 있을 것이다!

첫번째로 Semantic Segmentation의 Semantic의 사전적 의미는 "의미론의" 라는 뜻이다. 따라서 Semantic Segmentation이란 픽셀별로 라벨을 예측하는데, "의미"를 고려해 예측하는 task라고 추측할 수 있다. 그도 그럴게 왼쪽의 Semantic Segmentation 사진을 보면 도로, 양, 풀이 의미론적으로 나누어져 있다.
두번째로 Instance Segmentation의 Instance는 "개체"라는 뜻이다. 따라서 Instance Segmentation 이란 이미지 내의 개체를 하나하나 구분해 픽셀 라벨을 예측해주는 task라고 이해하면 된다. 왼쪽과 오른쪽 사진을 비교해보면 오른쪽의 양이 3마리로 구분된 것을 확인할 수 있다. 이는 각 객체를 하나의 라벨로 보기 때문에 그렇다.
위 두개의 방법론 중에서 본 포스팅에서는 Semantic Segmentation에 초점을 맞추려고 한다.
# Segmentation map
일단 Segmentation은 픽셀별로 라벨을 예측하는 모델이므로, 각 Segmentation 모델들은 output으로 "픽셀별 라벨"을 뱉을 것이다. 이러한 모델의 output을 우리는 Segmentation map이라고 하는데, 이를 이해하기 위해 아래 그림을 보자.
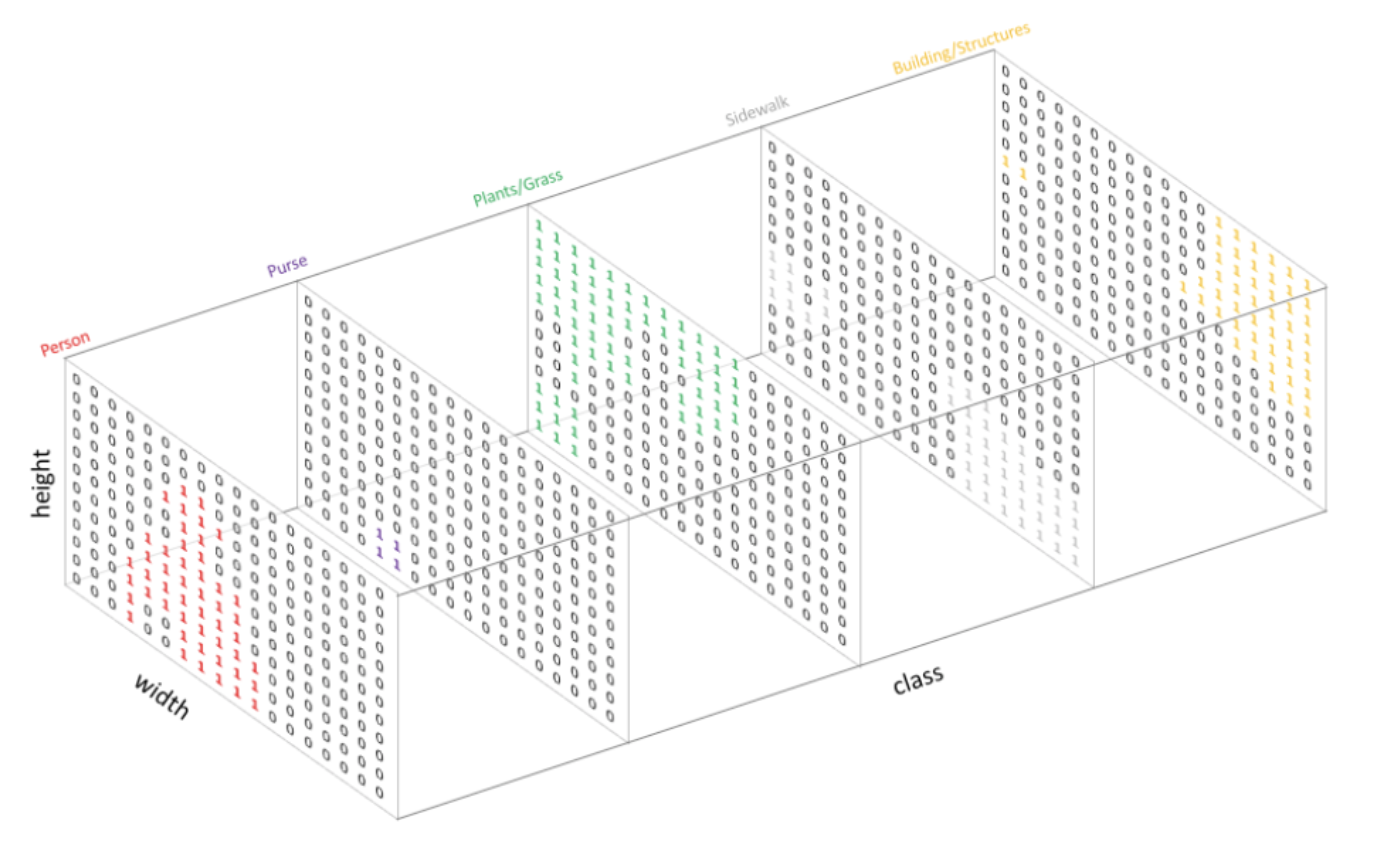
위 그림을 보면 서로 다른 색깔 채널은 앞선 그림의 5개의 class를 나타낸다. 각 라벨이 존재하는 부분에 원핫으로 표시해, 이를 class별 출력채널로 만드는 것이다. 앞선 그림에서 할머니가 존재했던 부분은 person 채널에서 표시되어 있고, 풀이 존재했던 부분은 세번째 채널에서 표시되어 있다. 따라서 이러한 각 class별 존재 여부가 담긴 채널들을 모두 합쳐 최종적으로 다음과 같은 output을 내놓는데, 이를 Segmentation map이라고 한다.
