![[Generation] 자세한 Pix2pixHD 논문 리뷰 (High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FHxBDt%2FbtrI2xgBUmz%2FAAAAAAAAAAAAAAAAAAAAAGq-3fXpFPnGeR3EtddBhqj3uWzPIrTUj6BzdVbDHwD1%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DZPOHpAjba7QX%252BAIsZrBF5plBb%252F0%253D)
오늘은 인턴에서 자주 접하고 있는 Pix2pixHD(CVPR 17')에 대해 포스팅해보려고 한다. 생성모델은 아직은 익숙치 않지만, 확실히 컴퓨터비전의 꽃이라고 할 만큼 재밌는 분야인 것 같다 ㅎㅎ
그럼 포스팅을 시작해보겠다! 네트워크를 중심으로 정리할 예정이다. 많은 내용을 꾹꾹 눌러담았다!
# Motivation
이 글을 읽는 독자들이라면 Pix2pix라는 생성 모델을 한번 쯤 들어본 적이 있을 수도 있을 것 같다. 일단 Pix2pixHD는 high-resolution(고해상도의)한 이미지를 생성해낼 수 있도록 기존 Pix2pix를 변형한 모델이다. 따라서 pix2pix를 밟고 올라오는 모델이라고 생각하면 되겠다. 기존의 pix2pix는 고해상도의 이미지 생성이 어려웠고, global한 생성은 가능하지만 인스턴스별로 디테일한 생성은 어려웠기 때문이다.
Pix2pix 처럼 여러종류의 이미지 생성이 가능하며, 한 이미지를 다른 이미지 스타일로 바꾸는 Image-to-image translation도 수행할 수 있다. 예를 들어 아래 그림처럼 segmentation image를 realistic한 image로 바꾸거나, 이미지의 boundary만 가지고 realistic한 image를 생성해낸다. 핵심은 이렇게 생성된 이미지가 2048 * 1024의 고해상도 이미지라는 것 !

# Model
그럼 이제 어떻게 pix2pix를 변형했는지 네트워크를 중심으로 알아보겠다. 일단 그 전에 pix2pix가 익숙치 않은 독자들을 위해 간단히 pix2pix에 대한 설명부터 추가하려고 한다.
1) Pix2pix ?
일단 Pixpix는 Conditional GAN을 기반으로 하는 Image-to-Image translation 모델이다. 일단 Conditional GAN을 기반으로 하므로, 모델에는 Generator(G)와 Discriminator(D)가 존재한다. (Image-to-Image translation 분야는 쉽게 말해서 Input 이미지의 스타일을 바꿔 Output으로 내놓은 분야를 말한다고 이해하면 된다)
설명을 쉽게 하기 위해 Segmentation 이미지(Semantic label)를 Realistic한 이미지로 바꾸어 생성하는 경우를 예로 들어 보겠다. 그렇다면 일단 Training을 위해서는 Segmentation과 실제 Realistic한 이미지가 pair로 모델에 들어가게 된다. Conditional GAN 구조이기 때문에, Segmentation이 주어질 때의 Realistic 이미지의 conditional distribution을 모델링하는 것이 목표이기 때문이다.
그리고 여기서 G와 D의 역할은 다음과 같을 것이라고 생각할 수 있다.
- G(생성자)의 역할 : Sementation을 Input으로 받아 최대한 실제처럼 보일 수 있는 가짜 Realistic 이미지를 생성
- D(구분자)의 역할 : G가 위에서 생성한 가짜 Realistic 이미지와 실제 Realistic 이미지를 구별
그렇다면 G와 D로 구성된 objective function(loss)는 어떻게 될까? 일반적으로 GAN의 loss는 G와 D의 min-max game으로 구성된다. 아래와 같이 말이다. 아래 수식에서 $s$는 segmentation을 의미하고, $x$는 Realistic한 GT 이미지를 의미한다.

결론적으로는, 다음과 같은 min-max objective를 최적화 시키게된다.
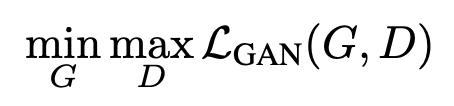
이러한 최적화를 시행하는데에 Pix2pix는 Generator로는 U-Net을 이용했고, Discriminator로는 Patch-based fully convolutional network를 이용했다. 하지만 이렇게 생성된 이미지는 low-resolution(저해상도) 라는 것이 문제였다. 따라서 Pix2pixHD는 이러한 loss framework는 유지하되 Generator와 Discriminator에 변화를 주었다.
2) Pix2pixHD ?
일단 pix2pixHD는 다음과 같은 두가지를 pix2pix에서 개선하려고 하였다.
- 2-1) High-resolution한 이미지 생성을 통한 Photo-realism 증대
- 2-2) Global한 특징보다 Instance에 집중한 디테일한 생성 및 다양한 이미지 생성
따라서 챕터를 위 두가지로 나누어, 각각 네트워크에서 어떤 것으로 이들을 이루려 했는지 포스팅하겠다.
2-1) For High-resolution Image
일단 고해상도 이미지 생성을 위해서, Pix2pixHD는 Coarse-to-fine generator와 Multi-scale discriminator, 그리고 Feature Matching loss로 G와 D의 구조를 변경하였다. 하나하나 차근차근 알아보자.
A. Coarse-to-fine Generator
일단 Coarse-to-fine이라는 의미에 답게 Global한 특징을 포착하는 Global generator(G1)와 이에 반면 Local한 특징을 포착하는 Local enhancer(G2)로 Generator를 구성하였다. 전반적인 Generator 구조는 다음과 같다.
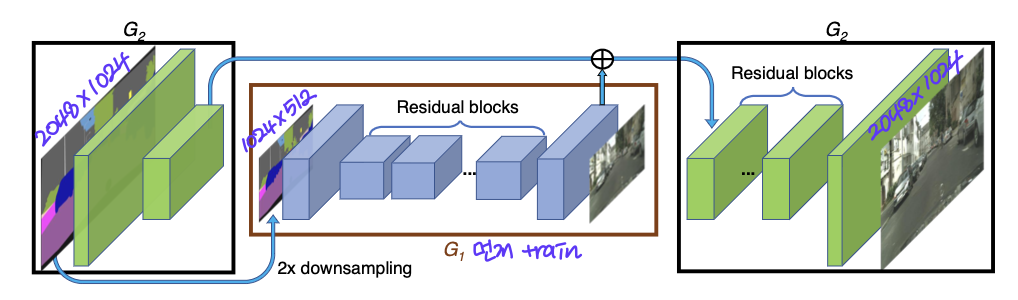
따라서 전체 모델의 Generator는 $G = {G1, G2}$로 나타낼 수 있다. 일단 Global generator를 먼저 train하고, 그 다음 local enhancer를 train하며 이들은 jointly하게 fine-tune 된다. 이를 통해 모델은 Global과 Local informantion을 효율적으로 aggregation할 수 있다. 두 Generator 들은 convolutional front-end, residual blocks, transposed convolutional back-end로 구성된다.
B. Multi-scale Discriminator
논문에서는 고해상도 이미지 생성을 위해서는 Receptive field가 커야함을 주장한다. 따라서 이를 위해 서로 다른 이미지의 scale에서 작동하는 Discriminator를 사용할 것을 주장한다.
따라서 Coarsest scale의 Discriminator는 보다 큰 receptive field를 갖게 되고, global view를 갖게 된다. 그리고 이러한 여러개의 Discriminator를 사용한 loss는 다음과 같이 Multi-task learning 문제로 생각할 수 있다. (첨언 : 각 task의 weight는 모두 같으므로, 단순 linear하게 task만 나눈 형태이다) 결론적으로 앞서 소개한 pix2pix의 loss 구조를 그대로 사용하지만, Discriminator는 scale별로 나눈 형태의 objective function을 사용한다.
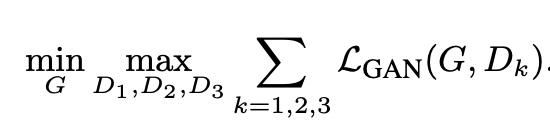
C. Feature Matching loss
앞서 소개한 Multi-scale Discriminator와 더불어 이러한 Multi layer에서 feature를 추출하고, GT real 이미지와 생성된 이미지의 feature representation을 매핑하기 위해 Feature Matching loss를 새로 사용한다. 간단히 L1 loss 형태인데, 이는 다음과 같다.
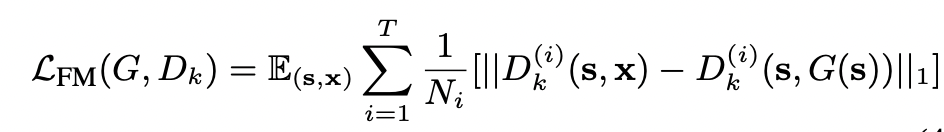
여기서 $T$는 총 Discriminator의 layer의 개수이고, layer마다 $K$개의 Multi-scale discriminator가 존재하는 것이다. 따라서 $D(s, x)$의 결과와 $D(s, G(s))$의 결과를 L1 loss를 통해 가깝게 만들려고 하며, 이는 학습과정을 안정화 시킨다고 저자들은 주장한다. Feature matching loss는 Discriminator에 대한 loss임을 기억하자.
위 Feature Matching loss를 더한 최종 Full objective는 다음과 같아진다. $lambda$는 Importance를 조정하는 factor이다.
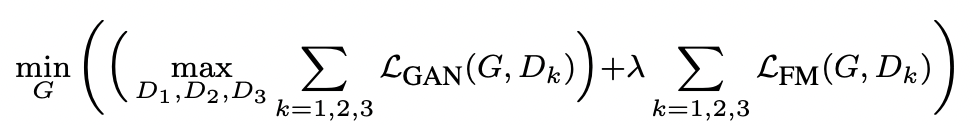
2-2) For Instance level Generation
이번에는 Instance에 집중한 디테일한 생성을 위한 네트워크의 구성 요소들을 알아보려고 한다. 일단 기존의 pix2pix는 Instance level의 생성에 집중하지 않았고, 다소 global 한 생성을 하는 경향이 있었다. 따라서 Instance-level에 조금더 집중하고 디테일한 생성을 위해 Instance Map을 사용하고, Instance-level Feature Embedding을 진행한다. 각각에 대해 알아보자.
A. Instance Map
일단 기존의 Semantic Segmentation과 달리, 저자들은 Instance Segmentation을 사용하는 것이 Object들의 boundary 정보를 더 잘 이용할 수 있어 명확한 이미지 생성에 도움을 줄 것이라고 주장한다. 아래와 같이 말이다! 특히 우측 이미지를 보면, Instance map을 사용한 것이 더 명확한 경계 형성에 영향을 주고 있음을 알 수 있다.

따라서 Instance Boundary Map을 만드는데 이는 주변 4개의 이웃 object가 다르면 픽셀 값을 1로, 나머지는 0으로 표시한 말 그대로 "boundary map"이며 one-hot vector representation으로 표현할 수 있다. 그리고 이러한 Instance Boundary Map은 채널별로 concat되어, segmentation과 real/synthesized image와 함께 Discriminator의 Input으로 들어간다.
B. Instance-level Feature Embedding + Kmeans
생성의 가장 관건은 one-to-many 문제라는 것이다. 이는 최대한 생성된 이미지가 Diverse 해야한다는 것인데, 이를 위해 Pix2pixHD는 Generator의 Input으로 Low-dimensional한 feature를 추가한다. 이러한 low-dimensional feature를 manipulating 할 수록 우리는 이미지 생성 프로세스에서 조금 더 flexible한 control이 가능해지고, 따라서 무한한 이미지를 생성해 낼 수 있다는 것이 본 네트워크의 취지이다.
이러한 low-dimensional feature를 생성하기 위해 Encoder Network $E$를 사용한다. 이는 전형적인 standard encoder-decoder network로, Generator/Discriminator와 jointly하게 학습된다. 그리고 GT 이미지 내 각 Instance에 해당하는 low-dimensional feature vector를 찾고자 하는게 목표이다. 중요한 점은 각 Instance 단위의 feature라는 것이다. 나아가 각 instance별로 feature의 일치를 보장하기 위해 Instance-wise Average pooling layer를 인코더 output에 추가해 Instance별로 average를 계산하도록 한다. 따라서 Average Feature는 각 Instance의 모든 픽셀 위치에 broadcast 되며, 이러한 프로세스는 아래와 같다.
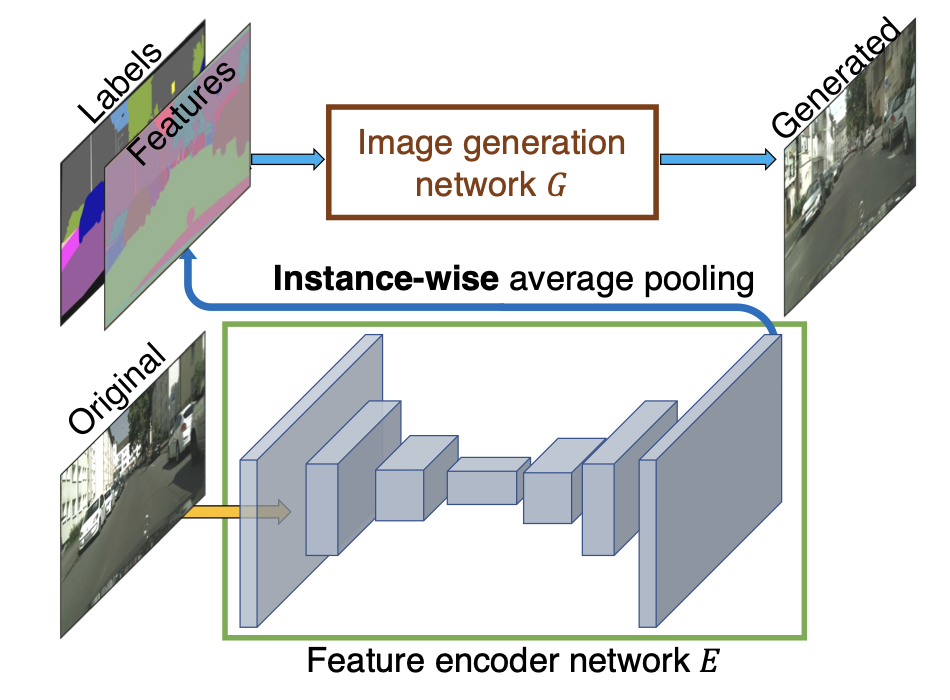
중요한 점은 이러한 low-dimensional feature가 generator의 input으로 segmentation과 함께 동시에 들어간다는 것이다.
그렇다면 이러한 프로세스에서 구체적으로 어떻게 생성된 이미지의 다양성을 보장할 수 있을까?
정답은 위 인코더를 이용해 train image 내 모든 Instance별로 feature를 얻어 이러한 feature를 대상으로 K-means clustering을 수행하는 것이다. 이러한 clustering은 각 semantic category에 대해 수행되고, 각 cluster는 style에 대한 feature를 담고 있다. 따라서 우리는 이러한 cluster 중에서 랜덤으로 선택하여, 이를 encoder feature로 삼는다. 그리고 이는 segmentation map과 concat 되어 비로소 Generator의 Input이 된다.
# Conclusion
지금까지 Pix2pixHD의 아키텍처에 대해 리뷰해보았다. 이러한 구조를 정리해보자면 다음과 같다.
1) For High resolution Image
A. Coarse-to-fine Generator
B. Multi-scale Discriminator
C. Feature Matching loss
2) For Instance level Generation
A. Instance Map
B. Instance-level Feature Embedding + Kmeans
References
[1] https://arxiv.org/pdf/1711.11585.pdf
'Computer Vision💖 > Generative model' 카테고리의 다른 글
| [Generation] OASIS(You Only Need Adversarial Supervision for Semantic Image Synthesis) 논문 리뷰 (0) | 2022.10.25 |
|---|