![[NLP] LORA : Low-Rank Adaptation of Large Language Models 논문 리뷰](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcbmwBn%2Fbtr73PwAFpP%2FAAAAAAAAAAAAAAAAAAAAAAN6uYy-74H0frwkJvewj9uhSQxzIvxt0FO7zue9KCNW%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DUKVosZDJTFFAQYtrGSqoGgqyNUw%253D)
반응형
# Problem statement
- Pre-trained model을 다양한 downstream task에 adaptation ex) Summarization
그리고 이는 주로 Fine-tuning으로 해결한다. - 일단 위 downstream task들은 training data of context-target pairs $z$ = ($x$, $y$) 로 표현됨
- Fully Fine-tuning?
- Downstream task의 log likelihood를 maximize 시키는 값을 찾겠다 ($x$, $y$는 example)
- 위 값은 거의 gradient descent 값으로 찾음 (w/ optimizer) > 전체 100% 파라미터 업데이트
- 하지만 위 gradient descent에는 이전 step의 정보를 저장해야하는 문제가 생김.
- Large Language Model은 파라미터 수가 상당한데, 이러한 모든 파라미터에 대한 이전 정보를 저장하는건 너무 무리임.
- 따라서 위 문제를 Fine-tuning 만으로 해결하기에는 어려움이 있다. 따라서 여러 parameter efficient tuning이 등장.

# Introduction
- 학습된 over-parameterized model이 실제로 낮은 low intrinstic dimension에 있다는 것에 영감을 받음. (기존의 over-parameterized model 내의 파라미터는 전부 필요하지 않음)
- Pre-trained weight를 고정된 상태(freeze)로 유지하면서, Adaptation 중 dense layer의 변화에 대한 rank decomposition matrices를 최적화
- 이를 통해 신경망 일부 dense layer를 간접적으로 train 시키는 것이 가능.
- 더 효율적이고, 기존의 fine tuning에 비해 나은 성능을 보여준다.
# Existing parameter efficient model adaptation?
- Transfer learning이 시작된 이래 많은 연구에서 parameter를 compute-efficient하게 model adaptation 하는 연구가 존재. 크게 아래 두가지 방향이 존재한다.
- 1) Adapter layer를 각각의 layer에 삽입하기
- 2) Input layer activation의 특정 form을 최적화 시키기
- 1) Adapter Layer 삽입
- Multihead attention의 결과값을 받아 Adapter에 삽입하는 sequential한 방법 > Inference latency(Inference시 지연시간)가 추가 발생한다고 반박
- 2) Prefix 튜닝
- Prefix-tuning은 최적화 하기 어렵고, 그 성능이 trainable parameter non-monotonically하게 변함을 관찰
- Adaptation을 위해 sequence length의 일부를 미리 떼어놔야 하기 때문에 downstream task를 처리하는데 사용할 수 있는 sequence length가 줄어듦
# LORA - Low-Rank Parametrized Update Matrices
- 모든 Dense layer에 적용 가능 (Language 뿐 아니라 Vision 쪽도 적용 가능)
- Down projection과 Up projection으로 구성
- 가정 : 가중치에 대한 update도 adaptation 중 intrinsic rank가 낮다고 가정 (기존의 over-parameter model이 intrinsic rank가 낮다고 주장하는 paper에서 영감을 받음)
- Pre-trained weight matrix $W_0$에 대해 이 행렬에 대한 update를 low-rank decomposition을 통해 아래와 같이 표현
- Gradient의 변화량 $\Delta W$을 $BA$로 approximate 하겠다는 것
- $W_0$는 frozen (gradient update를 수행 X)
- r 차원으로 줄였다가, 원래의 output feature의 dimension인 d로 늘린다. 그리고 merge 해준다.

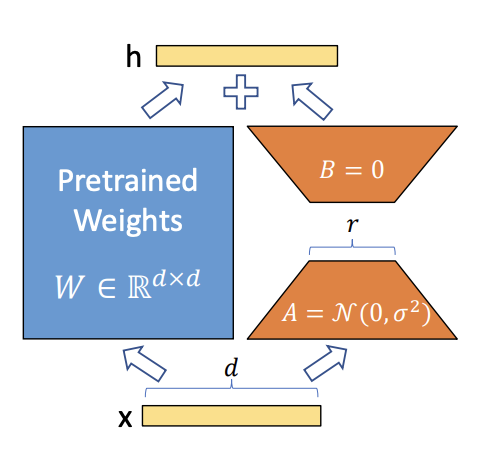
- 위 방법을 통해 Additional inference latency가 발생하지 않도록 함.
- Downstream task의 weight인 A, B 값을 더해줌으로서 merged weight가 fine-tuning된 weight가 되는 원리
- Inference 시에 그냥 이 layer를 통과시켜 주기만 하면 됨.
- Original weight 값으로 되돌리고 싶으면 위에서 merge한 weight를 그냥 빼주면 됨.
# Reference
https://www.youtube.com/watch?v=BJqwmDpa0wM
반응형
'NLP' 카테고리의 다른 글
| [TIL] In-context Learning with Long-context LLMs (0) | 2024.09.13 |
|---|---|
| [TIL] LLM as reward models/evaluators (#RLHF, #Self-improvement) (0) | 2024.08.30 |
| [NLP] Transformer(트랜스포머, Attention is all you need) (0) | 2021.02.09 |
| [NLP] Attention Mechanism (어텐션 메커니즘) (0) | 2021.02.09 |
| [NLP] Sequence-to-Sequence (Seq2Seq, 시퀀스 투 시퀀스) (0) | 2021.02.08 |