![[NLP] Transformer(트랜스포머, Attention is all you need)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FegrZoe%2FbtqWGLl8q62%2FAAAAAAAAAAAAAAAAAAAAANLrJqdWFHlyzv8kLi3e5T5LSneaEchh3eJObX43dC8h%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DS2dT0JAX1cf2IW%252FTFEzyrydI2V0%253D)
📚논문참고 Attention is all you need
1. 개요(기존 recurrent 모델의 한계)
- Long term dependency problem : 멀리 있는 단어는 예측에 사용하지 못하는 현상
ex) "저는 언어학에 관심이 많아 인공지능 기술 중 딥러닝을 배우고 있고, 그 중 자연어 처리가 가장 흥미롭습니다"라는 문장에서, '자연어처리' 단어를 생성하는데에 가장 중요한 의미를 갖는 단어는 '언어학'일 것임. 하지만 순환신경망 모델은 가까이 있는 딥러닝을 중요하게 인식할 가능성이 높을수도 있음. '딥러닝'으로 생성을 하면 '자연어처리'가 아니라 '컴퓨터비젼' 등을 생성할 수도 있음.
- Parallelization problem : 순환 신경명은 연쇄적으로 처리하기 때문에 병렬처리가 어려움
- 그럼 RNN 등의 recurrent 계열을 쓰지 말고, 아예 Attention으로 인코더 디코더를 구성한다면?
(Seq2Seq + Attention)

2. Attention Background
자세한 Attention 내용은 이전 게시글 참고
2021/02/09 - [딥러닝(DL) 📈/NLP] - [NLP] Attention Mechanism (어텐션 메커니즘)
1) Attention(Q, K, V) = Attention Value
어텐션 함수는 주어진 Query에 대해 모든 Key와의 유사도를 구하고, 이를 Key와 매핑된 각각의 Value에 반영함. 그리고 각각 Value를 Weighted Sum하여 Attention Value를 리턴함
2) Self Attention
Query, Key, Value가 모두 동일한 Attention (벡터의 출처가 같다는 것임)
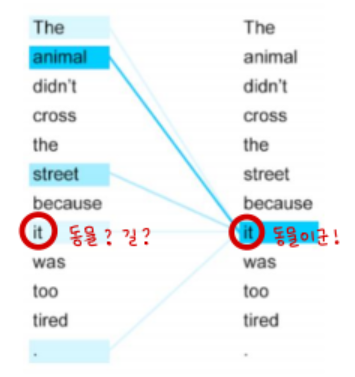
Self Attention을 활용하면 문장 내 단어간 유사도를 구할 수 있다는 장점이 있음
3) Scaled Dot-product Attention
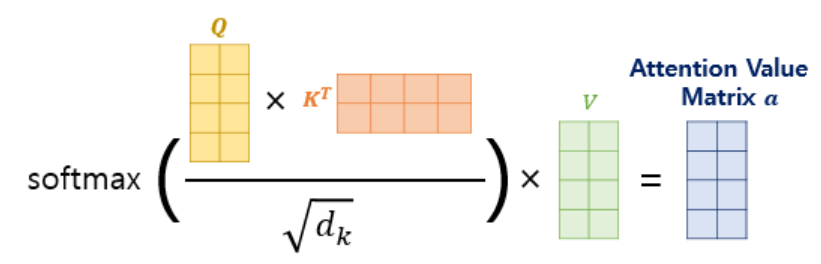
어텐션 함수를 단순 dot-product 가 아니라 스케일링해 사용하는 어텐션 종류
스케일링을 하는 이유는 분자의 곱이 너무 커지는 것을 막기 위해서임(너무 곱이 커지면 softmax 함수에 적용했을 때 기울기가 완만해져서 문제가 생김)

3. 모델 구성
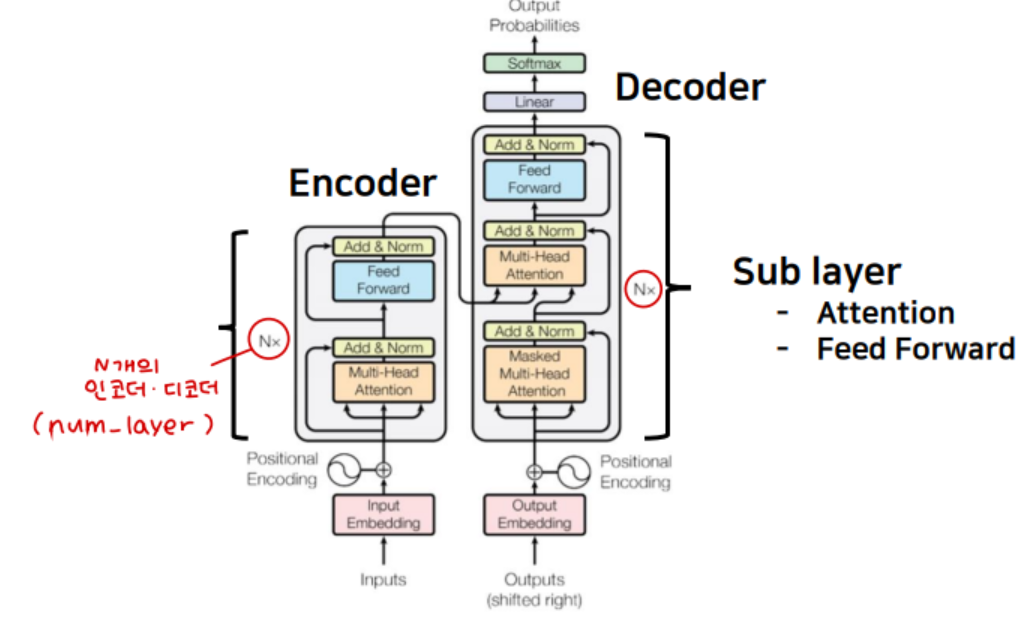
전반적으로 Seq2seq의 구조를 이루고 있기 때문에 인코더와 디코더로 구성됨
안에는 Attention과 Feed Forward Network로 이루어진 Sub layer가 각각 2개, 3개 존재함
인코더층과 디코더층은 여러겹 적재할 수 있는데 그 개수는 num_layer 하이퍼파라미터로 결정됨!
지금부터 Input 부터 인코더, 디코더 순으로 설명을 해보려 한당 ~_~
1) Positional Encoding

트랜스포머는 recurrent 계열의 모델을 사용하지 않으므로, 위치 정보를 반영할 방법이 필요함
따라서 임베딩 벡터에 위치 정보를 담은 인코딩 벡터를 더해서 이를 해결하고자 했음
임베딩 벡터의 크기와 위치 인코딩 벡터의 크기는 같음. 같아야 덧셈을 할 수 있으니까!
이는 논문에서 d_model로 표기되어있으며, 하이퍼파라미터임
Positional Encoding에 쓰이는 함수는 다음과 같음

인덱스가 짝수일때는 sin함수를, 홀수일때는 cos함수를 사용
삼각함수의 특성상 i가 작아지면 파장이 짧아져서 요동치고, i가 커지면 파장이 길어짐. 따라서 가까이 있는 단어를 비슷한 값을 가지게 할 수 있음
이렇게 도출된 포지셔널 인코딩 행렬을 시각화한 그림은 다음과 같다 (50X128 크기)

2) Encoder

A. Multi - Head Attention
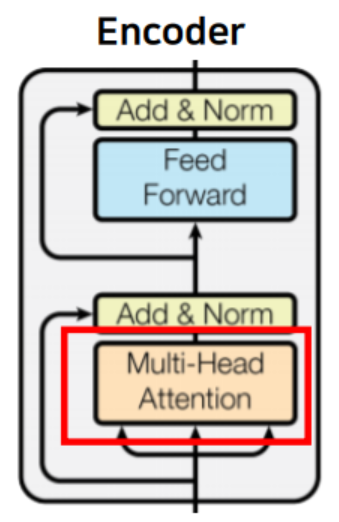
- 기본적으로 Self Attention 구조 ( Q = K = V )
- Q, K, V 모두 입력 문장의 모든 단어 벡터들에 해당
단어별 Q, K, V는 모든 단어 벡터에 각각 가중치 행렬을 곱해 얻을 수 있음
단 Q, K, V의 차원은 d_model보다 작음 (나중에 num_heads 만큼 병렬처리를 하기 위함)

또한 모든 단어 중, 시작 신호나 종료 신호 등 어텐션 연산에 무의미한 단어가 있음
이 단어는 Padding Mask 작업을 통해 Masking 해준다!
매우 작은 음수값을 넣어 softmax 함수가 이를 -∞ 로 인식하도록 한다
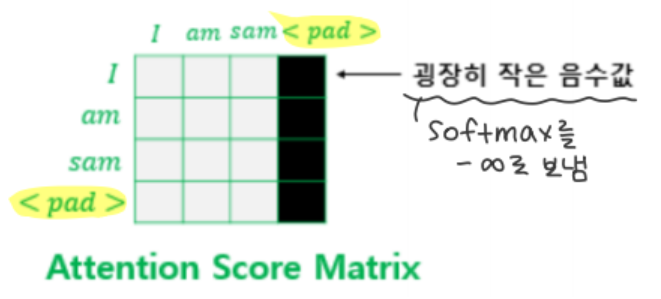
어텐션 종류는 Scaled dot-product attention을 사용함
스케일 된 어텐션 함수를 통해 어텐션 value를 추출하는 어텐션 매커니즘을 그대로 사용한다!
하지만, Multi-head 이름에 맞게 병렬처리를 하는 것이 이 어텐션의 특징!
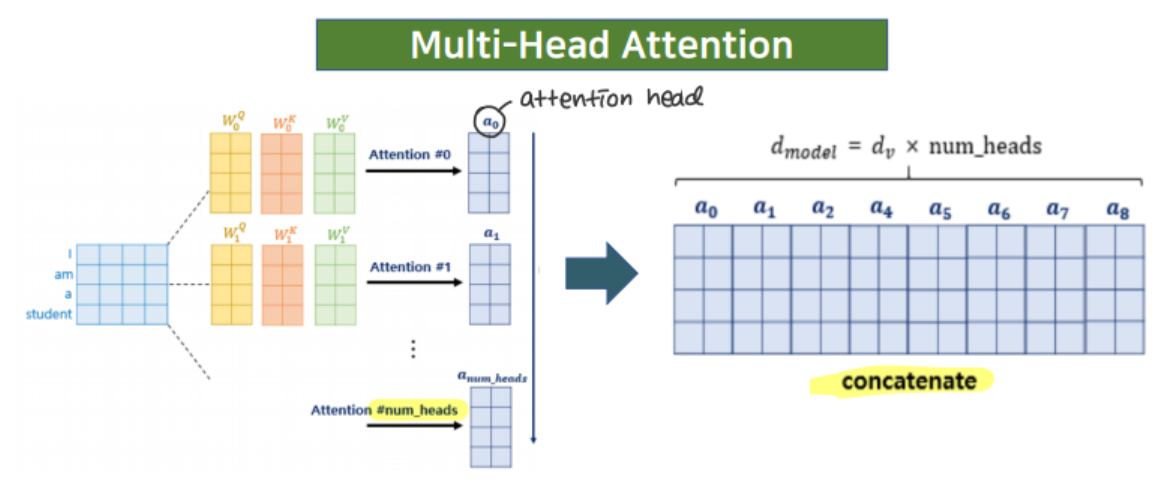
num_heads 만큼 병렬처리를 진행한 다음, 도출된 attention head를 concat해서 최종 attention value를 만든다


[21.02.12 첨언]
"Multi head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this. "
→ 이러한 병렬처리는 계산 효율 뿐 아니라 단일 어텐션으로는 얻기 어려운 representation을 얻는데 용이하다!
B. Add & Norm
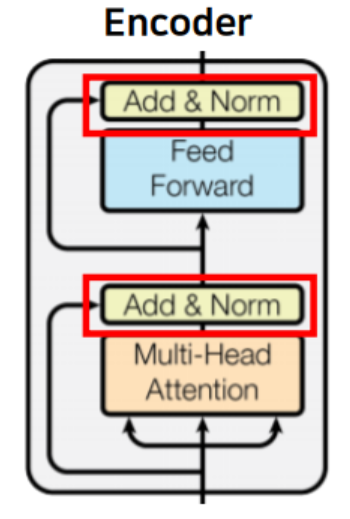
인코더와 디코더의 모든 sub layer 다음에 위치하는
잔차 연결층과 층 정규화 층!
원활한 학습을 돕기 위함이다
C. Feed Forward

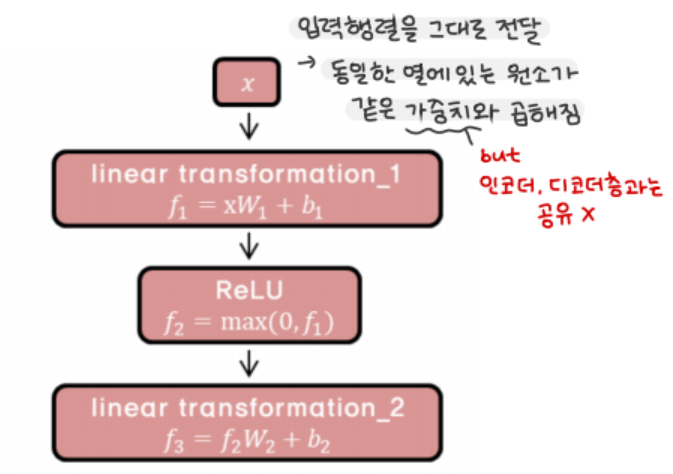
- 우리가 흔히 아는 Fully Connected Network
- 입력 행렬을 그대로 전달해 동일한 열에 있는 원소가 같은 가중치와 곱해짐
3) Decoder

기본적으로는 Encoder와 동일한 Multi-head attention, FF 구조임
A. Look Ahead Masked Multi Attention
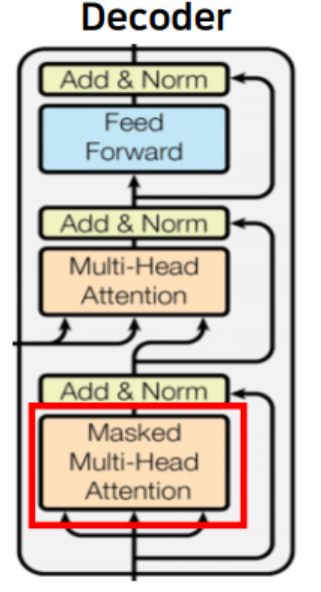
- 자신보다 미래에 있는 단어들을 참고하지 못하도록 Masking
(트랜스포머는 일반 seq2seq와 달리 input을 한번에 받기 때문에 현재 시점에서 미래의 단어를 미리 알고있는 현상이 발생. 따라서 이를 방지하고 순차적으로 테스트하기 위해 미래에 등장할 단어를 가려주는 Masking작업을 진행함)
- Look Ahead Mask 안에 패딩 마스크는 포함되어 있음
- 마스킹 과정은 패딩 마스크 과정과 동일함(음수를 대입)
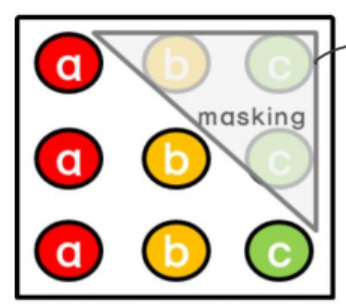
ex) 첫번째 줄 시점을 예측할 때는 미래의 b, c 시점을 가린다
B. Encoder Decoder Attention

- 유일하게 트랜스포머에서 Self - Attention 층이 아닌 layer
- Query는 디코더 행렬, Key와 Value는 인코더 행렬에서 받는다
- Multi-head attention을 수행하는 다른 과정은 동일하다!
C. Feed Forward
앞선 Encoder의 작용과 동일하므로 생략
'NLP' 카테고리의 다른 글
| [TIL] In-context Learning with Long-context LLMs (0) | 2024.09.13 |
|---|---|
| [TIL] LLM as reward models/evaluators (#RLHF, #Self-improvement) (0) | 2024.08.30 |
| [NLP] LORA : Low-Rank Adaptation of Large Language Models 논문 리뷰 (0) | 2023.04.04 |
| [NLP] Attention Mechanism (어텐션 메커니즘) (0) | 2021.02.09 |
| [NLP] Sequence-to-Sequence (Seq2Seq, 시퀀스 투 시퀀스) (0) | 2021.02.08 |