![[XAI] OpenAI CLIP 논문 리뷰[1] - 전반적인 아키텍처](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FVGte6%2Fbtq9IEniUZC%2FAAAAAAAAAAAAAAAAAAAAAIWw33fmg093M1vQuRo2b2n2RxCGg9zSBy4Iw1gZPt7w%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3D01mChcKQfX16ktiY6906UGaqELQ%253D)
오늘은 OpenAI에서 2021년 상반기에 나온 최신 모델인 CLIP(Contrastive Language-Image Pretraining) 논문에 대해 포스팅하려고 합니다. 제가 이해한 바를 정리한 내용이니 댓글로 잘못된 내용이 있다면 꼭 알려주세요 👀
Introduction
이 글을 보시는 분들이라면 Bert, GPT 등의 모델을 한번 쯤은 들어보셨을 것입니다. 이 두 모델 모두 트랜스포머에 기반을 둔 모델인데요, 또한 이들은 모두 Raw text로부터 바로 사전학습(Pre-training) 한다는 공통점이 있습니다. 이들은 아시다시피 NLP 분야에서 뛰어난 성능을 보이고 있죠. 이렇게 사전학습 방식은 자연어 처리 분야에서는 정말 뛰어난 성과를 내고 있습니다.
하지만 이러한 사전학습 방식이 컴퓨터 비전분야에서도 뛰어난 성과를 낼 수 있을까요?
위의 예시와 같은 뛰어난 성능에도 불구하고 아직 자연어를 이미지 representation learning에 사용하는 경우는 매우 드뭅니다. 왜일까요? 바로 성능이 매우 낮기 때문입니다. 현재 CNN 계열의 컴퓨터 비전 모델은 뛰어난 성능을 보이고 있죠. 하지만 Li et. l.(2017) 에서 ImageNet 데이터셋에 zero-shot setting을 적용한 결과 약 11.5%의 acc를 보였습니다. 이는 현저히 낮은 수치죠.
대신에 weak supervision을 준 환경에서는 성능 향상을 가져오긴 했습니다. 하지만 논문에서 이러한 방법은 zero-shot 능력을 제한시키게 된다고 주장합니다. (zero shot learning이 친숙하지 않은 분은 여기를 참고해주세요)
따라서 본 고에서는 CLIP을 통해 새로운 representation learning 방법을 제안합니다. CLIP은 4억개의 이미지, 텍스트 쌍으로 학습한 모델이며, 후에 서술하겠지만 매우 강력한 성능을 보여줍니다. 그렇다면 왜 굳이 "자연어" supervision 기법을 이용하는 것일까요? 다음 장에서 알아보도록 하겠습니다.
Natural Language Supervision
CLIP의 핵심은 텍스트에 포함된 supervision으로 학습하는 것이라고 할 수 있습니다. 이렇게 텍스트를 이용해 학습하는 것이 다른 학습방법에 비해 무엇이 좋은 것일까요?
첫째는, 라벨링을 요구하지 않기때문에 확장에 용이하다는 장점이 있습니다. 기존의 컴퓨터비전 분야는 라벨링 과정이 필수적입니다. 하지만 텍스트를 이용하게 되면 그러한 과정이 필요가 없어지는 것입니다. 둘째는, 언어에 대한 representation까지 학습함으로써 유연한 zero-shot transfer를 가능하게 한다는 장점이 있습니다. 그럼 CLIP은 어떤 방식으로 train을 진행하는걸까요?
CLIP의 전반적인 아키텍처
전반적인 CLIP의 아키텍처는 다음과 같습니다.
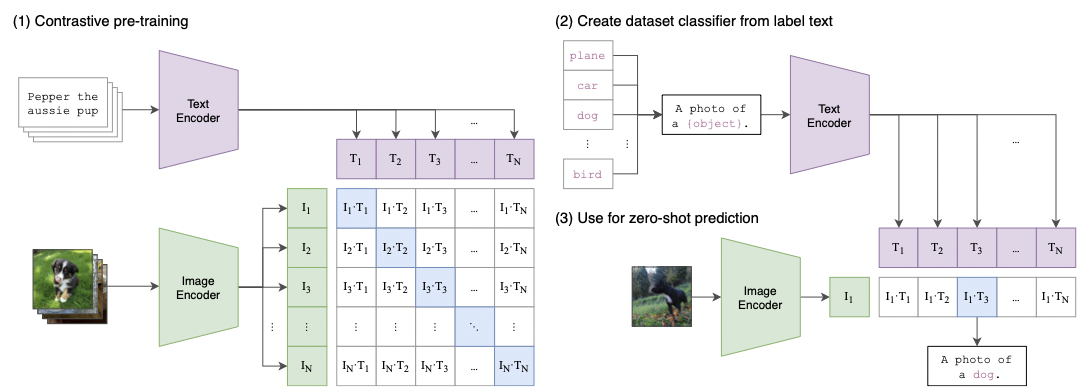
그림의 (2), (3)번은 다음 게시글에서 다루기로 하고, 이번 포스팅에서는 (1)번의 pre-train 과정에 집중해보기로 하겠습니다. CLIP은 기본적으로 (텍스트, 이미지)가 한 쌍의 input으로 주어지는 모델입니다. 따라서 N개의 (텍스트, 이미지) 쌍의 배치가 주어진다고 할 때, CLIP은 그림에서 보시다시피 N*N의 가능한 (텍스트, 이미지) 쌍을 예측하도록 학습됩니다. (그림의 바둑판이 이에 해당합니다.)
따라서 만약 대각선에 위치한 실제 (텍스트, 이미지) 쌍이라면, 이들의 코사인 유사도를 최대화 하고, 나머지 쌍들은 코사인 유사도를 최소화 하는 방향으로 이미지 인코더와 텍스트 인코더를 함께 학습하게 되는 것입니다. 이를 통해 multi-modal 임베딩 공간을 학습하게 됩니다. 논문에서 제시된 numpy 기반 간략한 코드를 보시면 이해가 쉽습니다.

우선 코드에 보시다시피, 이미지 인코더와 텍스트 인코더로 feature를 추출한 후, 이들을 projection을 통해 multi modal embedding space로 encoder의 representation을 매핑시킵니다. 그 후, 이렇게 multi model 임베딩 공간에 매핑된 벡터끼리 코사인 유사도를 구하고, 이에 대해 cross entropy를 이용해 loss를 구하는 형식입니다. 참고로 위에서 언급한 projection은 linear한 projection입니다.
하지만 이러한 과정에는 이미지 인코더와 텍스트 인코더가 먼저 필요할 것인데요, 이 둘은 어떻게 이루어져 있을까요?
< Image Encoder >
본 고에서는 이미지 인코더를 두개의 구조로 고려했는데, 하나는 ResNet-50 이며, 다른 하나는 Vision Transformer(ViT) 입니다.
1) ResNet-50
본 고에서는 원래 ResNet 에서 수정된 버전을 사용했는데, global average pooling을 attention pooling으로 대체하고 ResNet-D 버전을 사용하였습니다.
2) ViT (Vision Transformer)
또한 최근 대두되고 있는 Vision Transformer도 사용하였는데요, layer normalization을 추가하는 것 외에 기존의 모델을 따로 수정하지는 않았다고 합니다.
< Text Encoder >
텍스트 인코더로는 Transformer를 사용하였는데, max length는 76으로 제한하였습니다.
Results
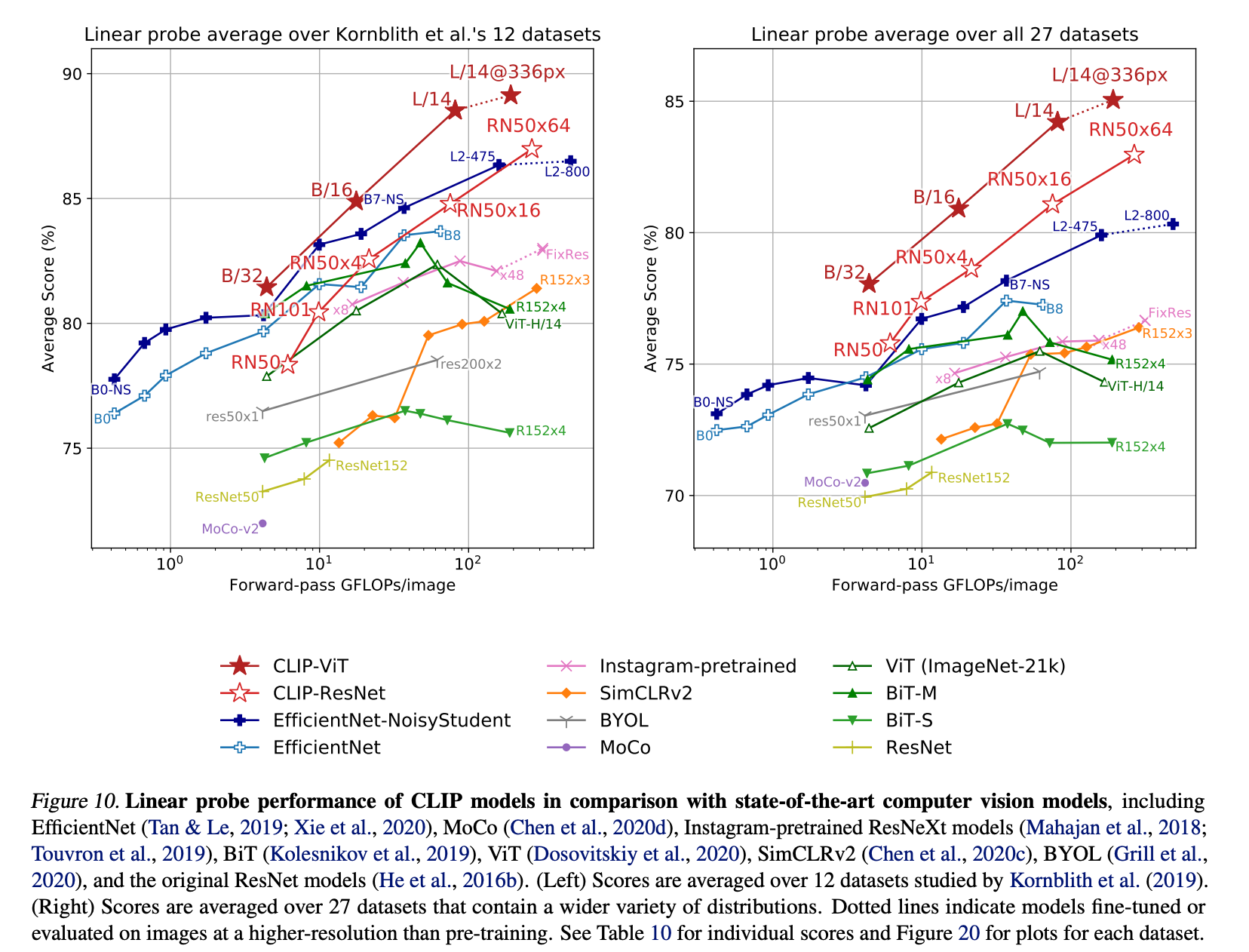
위 그림에서 보시다시피 CLIP은 다른 SOTA 모델과 비교했을 때 더 나은 score를 보이고 있음을 확인할 수 있습니다. 또한 CLIP은 텍스트 간의 연관성 또한 학습하기 때문에 다른 domain의 태스크에도 강력하게 작동한다는 장점이 있습니다.
지금까지 CLIP의 전반적인 아키텍처와 등장배경 등에 대해 간략히 알아보았습니다. zero-shot 관련 experiments 등은 다음 게시글에서 포스팅하도록 하겠습니다.
References
[0] https://simonezz.tistory.com/88?category=892979
[1] https://arxiv.org/pdf/2103.00020.pdf
'Computer Vision💖 > Multimodal' 카테고리의 다른 글
| [Multimodal] 멀티모달 러닝 (Multimodal Learning)에 대한 아주 기초적인 이해 (1) | 2024.01.18 |
|---|---|
| [VQA] Zero-shot VQA + Domain Adaptation VQA 분야 개괄 (0) | 2023.08.01 |
| [XAI] Generating Visual Explanations(2016) - 이미지 분류에 대한 설명을 생성하는 알고리즘 (0) | 2021.08.15 |
| [XAI] OpenAI CLIP 논문 리뷰[3] - Domain Generalization (2) | 2021.07.19 |
| [XAI] OpenAI CLIP 논문 리뷰[2] - Zero shot & Representation learning (0) | 2021.07.17 |