![[XAI] OpenAI CLIP 논문 리뷰[3] - Domain Generalization](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcIYKDO%2Fbtq9NQvDJIP%2FAAAAAAAAAAAAAAAAAAAAAAm9tgaRIXYxjnKwKMfVi0ZLBCpTRZps5hCLElM52SEo%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3Dck9USo7i2J8YuNaK3tC4kUxiph0%253D)
오늘은 CLIP에 대한 마지막 포스팅으로, CLIP 논문의 마지막 실험 챕터인 "Robustness to Natural Distribution Shift" 에 대해 포스팅하겠습니다. 역시 잘못된 부분이 있다면 댓글 부탁드립니다 👀 또한 CLIP의 전반적인 개념과 zero-shot, representation learning의 실험과 내용에 대해 궁금하신 분은 제 이전 게시글을 참고 부탁드립니다.
[딥러닝(DL) 📈/XAI] - [XAI] CLIP(Contrastive Language-Image Pre-training) 논문 리뷰
[딥러닝(DL) 📈/XAI] - [XAI] Zero shot & Representation learning 에서의 CLIP - 논문리뷰 + Code
우선 챕터에 들어가기 전에 'Distribution Shift'에 대해 먼저 이해가 선행되어야 할 것 같은데요, 관련 개념을 먼저 소개하도록 하겠습니다. 이 개념은 Domain generalization과도 관련있는 개념입니다.
Distribution shift 와 Domain Generalization

머신러닝의 고질적인 문제는 단연 Overfitting일 것입니다. 특히 우리는 train과 test data를 보통 같은 sample distribution에서 뽑았다고 가정하죠. 하지만 이러한 가정으로 인해 우리는 항상 학습 과정에서 Generalization 문제를 경험합니다. 특히 CLIP 논문에서도 딥러닝 모델이 인간보다 성능이 낮은 이유는 train dataset 부터 'in-distribution performance'를 향상시키도록 학습하기 때문이라고 지적합니다. (저는 이 'in-distribution performance'라는 단어가 개인적으로 굉장히 와닿았습니다)
이러한 근본적인 기계학습의 문제를 풀어나가고자 하는 분야가 있습니다. 바로 'Domain Generalization(DG)' 입니다. (앞으로 Domain Generalization을 편의상 DG라고 칭하겠습니다.) 그리고 앞서 언급한 train data와 test data의 distribution 차이를 보통 우리는 'Domain(Distribution) shift' 라고 칭합니다. 이러한 'Domain shift'에 대응하기 위해DG는 domain에 불변(invariant)한 features를 뽑는데에 목적을 둡니다.
이러한 분야에서 CLIP의 개념과 접목해보면, CLIP은 학습 시 Natural language supervision을 받으며 제로샷 학습에도 매우 뛰어난 성능을 보이는 pretraining입니다. 따라서 본 고의 저자는 이러한 CLIP이 domain shift 에도 매우 효과적인 모델이 될 것이라 역설합니다. 그리고 아래 그림처럼 결과적으로 CLIP은 이러한 distribution shift에도 기존 지도학습 모델보다 매우 뛰어난 성능을 보입니다. 그럼 지금부터 그 실험 과정을 차근차근 살펴보겠습니다.

Robustness의 구분
도메인의 변화에도 효과적인 모델이라면 상식적으로 모델의 robustness가 높을 것이라고 추측할 수 있을텐데요, 따라서 본 고에서는 robustness의 개념을 두가지로 나눕니다. 이는 Taori et al.(2020)의 개념을 참고한 것인데요, robustness의 두가지 구분은 Effective robustness와 relative robustness 입니다. 논문에서 언급된 간단한 두 개념을 살펴보면 다음과 같습니다.
- Effective robustness : Distribution shift 하에서 정확도의 개선
- Relative robustness : Out-of-distribution 에서의 정확도의 개선
그리고 본 논문에서는 이 두 robustness를 동시에 증가해야 함을 역설하며, robustness에 대한 측정을 Zero-shot CLIP으로 진행합니다. Zero-shot CLIP이란, CLIP이 pre-training model 이기에, pre-train 후 downstream task를 제로샷 방식으로 진행했음을 뜻합니다. (자세한 설명은 제 이전 게시글을 참고해주시면 감사하겠습니다) 그럼 기존의 supervision models과 비교한 Zero-shot CLIP의 성능은 어떨까요?
Zero-shot CLIP의 Robustness
우선 직관적으로 제로샷 러닝의 특성상 특정 분포에서 train 되지 않기 때문에, 어떤 분포와 상관관계가 미미한 것은 당연할 것입니다. 따라서 본 고에서는 이러한 Zero-shot CLIP을 이용해 특히 위에서 언급된 robustness 중 effective robustness 를 개선했다고 언급합니다. 그 실험 결과를 앞에서 언급했던 다음 그림과 함께 보시죠.
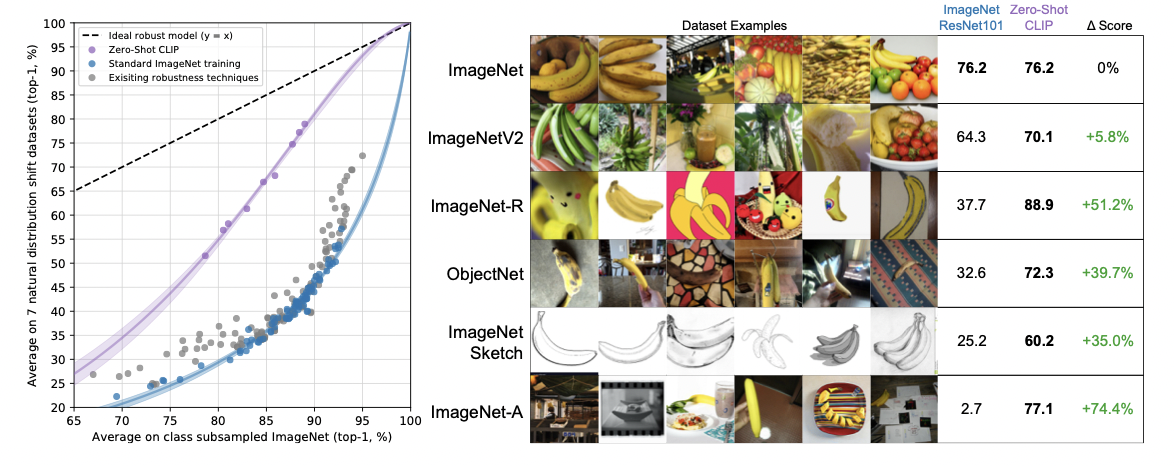
위 그림 중 우선 좌측의 그림은 robustness gap을 나타낸 그래프입니다. 검정색 점선은 모든 distribution에 동일하게 작용하는 ideal robust model을 나타내죠. 보라색의 zero-shot clip 모델은 이러한 ideal robust model과의 robustness gap을 75%이상 줄일 수 있었다고 합니다. 또한, 우측의 그림은 바나나의 distribution shift 에서 Zero-shot CLIP은 기존의 ResNet-101보다 다른 도메인에서 훨씬 우수한 성능을 보임을 미루어 짐작할 수 있게 해줍니다.

또한 위의 그래프로 미루어 봤을 때 Supervised adaptation to ImageNet은 Acc를 9.2%정도 증가시키지만, robustness를 감소시키는 경향이 있을 것입니다. 하지만 Zero-CLIP은 향상된 robustness를 보여줍니다(그래프의 기울기). 하지만 이 robustness가 모든 데이터에서 적용되는 것은 아니며, 이는 우측의 그래프로 짐작할 수 있습니다.
지금까지 약 3개의 게시물에 걸쳐 CLIP에 대해 자세히 리뷰했습니다. 잘못된 부분은 댓글로 꼭 지적해주시면 감사하겠습니다 😊😊
'Computer Vision💖 > Multimodal' 카테고리의 다른 글
| [Multimodal] 멀티모달 러닝 (Multimodal Learning)에 대한 아주 기초적인 이해 (1) | 2024.01.18 |
|---|---|
| [VQA] Zero-shot VQA + Domain Adaptation VQA 분야 개괄 (0) | 2023.08.01 |
| [XAI] Generating Visual Explanations(2016) - 이미지 분류에 대한 설명을 생성하는 알고리즘 (0) | 2021.08.15 |
| [XAI] OpenAI CLIP 논문 리뷰[2] - Zero shot & Representation learning (0) | 2021.07.17 |
| [XAI] OpenAI CLIP 논문 리뷰[1] - 전반적인 아키텍처 (1) | 2021.07.15 |