![[CV] Adversarial Learning(적대적 학습)이란? + 응용](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FQlV94%2FbtrAhdD2Z1o%2FAAAAAAAAAAAAAAAAAAAAALdw7W4X8LPaydtrFsolmsUzVEQehfnUALNcptOd_JfI%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DMS4EP3MkmayKYrkS5fYu9w3jPZk%253D)
오늘은 PointAugment paper를 읽다가 main 원리로 나온 Adversarial learning에 대해 포스팅해보려고 한다. 주로 적대적 학습이라고 하는데, 그냥 내가 이해한 내용을 간단히 정리해보려고 한다. (미팅준비로 인해... 자세한 포스팅은... 미뤄두겠다.)
# Idea
우선 적대적 학습에서, 적대적(adversarial)이란 '서로 대립관계에 있는' 이라는 뜻이다. 흔히 들어봤을 GAN의 속 의미가 Generative adversarial networks 인데, 여기 들어가는 adversarial과 비슷한 의미라고 이해할 수 있다. GAN은 흔히 두개의 네트워크가 경쟁하며 학습하는 모델이라고 잘 알려져 있는데, Discriminator를 잘 속이기 위한 데이터를 Generator가 얼마나 잘 만들 것인지가 중요한 문제이다.
여기서 중요한 부분은 '잘 속이기 위한'이다. 오늘 소개할 적대적 학습의 방식도 신경망을 '잘 속이기 위한' 방법으로 알려져있기 때문이다. 우리는 오늘 분류기를 속이기 위한 방법을 알아볼 것이다.
분류기를 속이는 방법이란 그렇게 어렵지 않다. 아래 두 그림을 보자.
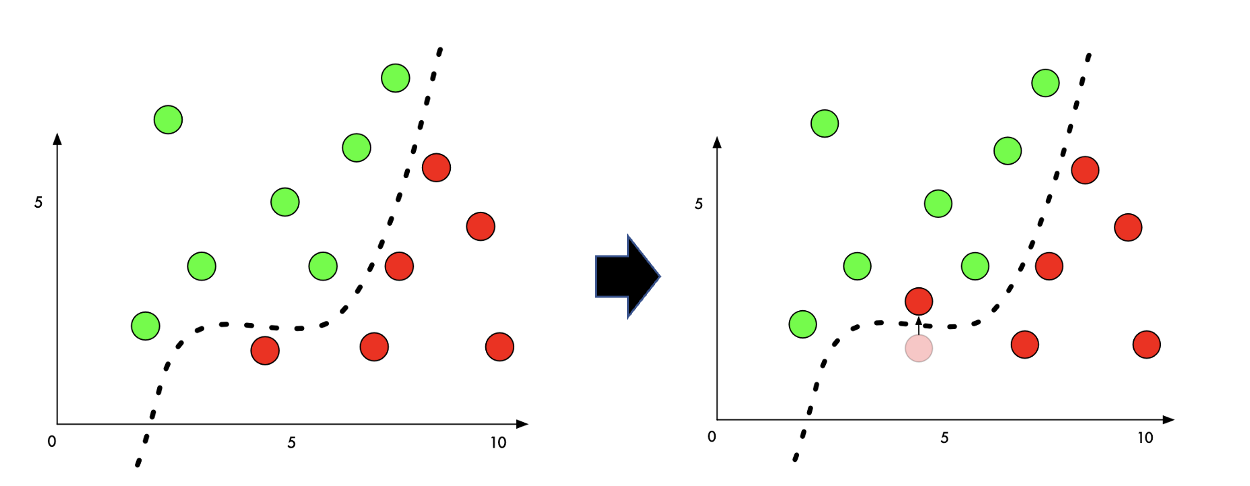
왼쪽은 연두와 빨강을 아주 잘 분류한 분류기이다. 이 분류기를 오분류를 위해 조작하려면, 오른쪽처럼 빨간색 point를 결정경계에서 아주 살짝 이동해주면 될 것이다. 하지만 이렇게 어떻게 "살짝" 움직일 것인가는 어려운 문제이다. 왜냐면 우리가 학습시켜야 할 NN은 위 2차원 그래프 처럼 작은 차원의 데이터도 아닐뿐더러, 아주 복잡한 합성곱의 연속이기 때문이다. 조작해야할 weight의 값이 수천개나 될 수 있다.
따라서 우리는 네트워크의 가중치를 직접 수정하는 것보다, 신경망에 입력하는 이미지를 조정하는 방법으로 적대적 학습(Adversarial network)을 구현할 수 있다. Input image에서 속임수를 쓰는 것이다.
# Process
우선 흔히 Adversarial Network는 다음과 같은 프로세스로 구현된다. 아래 프로세스를 이해하면, paper에서 응용되는 적대적 학습 개념을 이해하기에는 어려움이 없을 것이다. 핵심은 Real image와 조금 변형된 image를 네트워크에 제공해, 변형된 image가 Real image와 가까워지도록 학습한다는 것이다.

위 프로세스를 절차로 설명해보면 다음과 같다.
- 원본 Image와 조금 변형된 이미지를 네트워크에 제공한다. (여기서 변형된 이미지란 픽셀의 일부분을 변형시킬수도 있고, augmentation을 한 이미지일 수도 있다)
- 1번에서 제공한 Image를 네트워크가 예측하도록 하고, Real Image와 얼마나 차이나는지 확인한 후 역전파를 이용해 Real Image에 대한 output과 가까워지도록 만든다.
- 1, 2를 반복한다.
즉, 변형된 Image에도 잘 대응할 수 있도록 네트워크의 파라미터(가중치)를 조정하는 과정으로 이해하면 될 것 같다.
# Application
그렇다면 이러한 적대적 학습 방식이 어떻게 쓰이는지 간단한 응용을 소개하고 포스팅을 마치려고 한다. 사실 내가 요즘 읽고 있는 PointAugment: an Auto-Augmentation Framework for Point Cloud Classification (CVPR 2020, Oral) 라는 paper이다. 이 paper의 아키텍처를 보면 위 개념적인 내용의 이해가 쉬울 것 같아 가져왔다!

이 paper는 pointcloud를 augmentation하는 augmentor를 학습시키는 것을 목표로 하는 paper이다. (무려 CVPR에서 Oral까지 받은 아주 아주 잘 써진 paper인 것 같다! 개인적으로 재밌게 읽었다는..!) 따라서 위 아키텍처를 보면 Classifier에 augmented된 sample과 원래의 origin sample이 각각 들어가는 형태임을 알 수 있다. 여기서 augmented된 sample이란 앞서 설명한 변형된 input image에 해당한다고 이해하면 될 것 같다.
위 Pointaugment의 loss function도 어떻게 augmented된 sample과 원래의 sample의 거리를 좁혀 학습할 것인가?의 문제를 풀기 위해 설정된다. 간단히 소개하면 다음과 같다.

여기서 L(P')는 augmented sample의 분류기 결과이고, L(P)는 원래의 sample의 분류기 결과라고 보면된다. ('가 붙은 것이 augmented sample이다.) 특히 Classifier loss에서 두 sample의 feature의 유클리디안 거리를 좁히는 부분이 들어가있음을 알 수 있다.
References
'Computer Vision💖 > Basic' 카테고리의 다른 글
| [CV] 이미지들 사이의 관계를 T-SNE plot으로 나타내기 (0) | 2023.08.27 |
|---|---|
| [CV] ResNet-18로 특정 Image의 feature 추출하기 (PyTorch) (0) | 2022.05.30 |
| [CV] Self-supervised learning(자기주도학습)과 Contrastive learning - 스스로 학습하는 알고리즘 (4) | 2021.07.02 |
| [CV] AlexNet(2012) 논문을 code로 구현 해보자 (Keras, PyTorch) (0) | 2021.06.25 |
| [CV] AlexNet(2012)의 구조와 논문 리뷰 (0) | 2021.06.23 |