![[CV] AlexNet(2012) 논문을 code로 구현 해보자 (Keras, PyTorch)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FJ29tU%2Fbtq8avdCrY7%2FAAAAAAAAAAAAAAAAAAAAALkreDrtHXtH2IFlbFClBJr-3RClCPRFdOHjVt3FDDO7%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DNCFoAj9gBPTRncUez0SdRaPsI7I%253D)
이번 포스팅에서는 지난번 포스팅했던 AlexNet을 Keras와 PyTorch로 각각 구현하고 적용해보고자 합니다. 사실 저는 Keras에 훨씬 익숙하기에, 메인 code들은 Keras로 작성하겠습니다. 이론 설명은 지난번 포스팅을 참고해주세요!
2021.06.23 - [딥러닝(DL) 📈/CV] - [Vision] AlexNet(2012)의 구조와 논문 리뷰
[Vision] AlexNet(2012)의 구조와 논문 리뷰
오늘은 Deep한 CNN의 발전에 가장 큰 영향을 준 AlexNet(2012)에 대해 포스팅하고자 합니다. AlexNet은 2012년에 개최된 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 에서 우승을 차지한 아키텍처..
daeun-computer-uneasy.tistory.com
기본 아키텍처 파악
우선 구현 전에 논문에 소개된 AlexNet의 아키텍처를 살펴보겠습니다.

AlexNet은 [Input layer - Conv1 - MaxPool1 - Norm1 - Conv2 - MaxPool2 - Norm2 - Conv3 - Conv4 - Conv5 - Maxpool3 - FC1- FC2 - Output layer] 으로 구성되어 있습니다. 논문의 dataset은 1000개의 class를 분류하는 것이었기 때문에 output node는 1000이 됩니다. 이러한 아키텍처를 각각 PyTorch와 Keras로 바로 구현해보겠습니다.
PyTorch 구현
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
##### CNN layers
self.net = nn.Sequential(
# conv1
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4),
nn.ReLU(inplace=True), # non-saturating function
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2), # 논문의 LRN 파라미터 그대로 지정
nn.MaxPool2d(kernel_size=3, stride=2),
# conv2
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
# conv3
nn.Conv2d(256, 384, 3, padding=1),
nn.ReLU(inplace=True),
# conv4
nn.Conv2d(384, 384, 3, padding=1),
nn.ReLU(inplace=True),
# conv5
nn.Conv2d(384, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
##### FC layers
self.classifier = nn.Sequential(
# fc1
nn.Dropout(p=0.5, inplace=True),
nn.Linear(in_features=(256 * 6 * 6), out_features=4096),
nn.ReLU(inplace=True).
# fc2
nn.Dropout(p=0.5, inplace=True),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
# bias, weight 초기화
def init_bias_weights(self):
for layer in self.net:
if isinstance(layer, nn.Conv2d):
nn.init.normal_(layer.weight, mean=0, std=0.01) # weight 초기화
nn.init.constant_(layer.bias, 0) # bias 초기화
# conv 2, 4, 5는 bias 1로 초기화
nn.init.constant_(self.net[4].bias, 1)
nn.init.constant_(self.net[10].bias, 1)
nn.init.constant_(self.net[12].bias, 1)
# modeling
def forward(self, x):
x = self.net(x) # conv
x = x.view(-1, 256*6*6) # keras의 reshape (텐서 크기 2d 변경)
return self.classifier(x) # fc
Keras 구현
Functional API를 사용하였습니다. Keras에는 LRN 모듈을 사용하는데에 이슈가 있어 BatchNormalization을 사용하였습니다.
# modeling(functional API)
input_shape = (224, 224, 3) # 논문에서 제시된 shape
x = Input(shape = input_shape, name='INPUT')
# CONV
conv1 = Conv2D(filters=96, kernel_size=11, activation='relu', strides=4, name='CONV_1')(x)
pool1 = MaxPooling2D((3,3), strides=2, name='POOL_1')(conv1) # overlapped pooling
# lrn1 = local_response_normalization(conv1,depth_radius=5, bias=2, alpha=0.0001, beta=0.75)
lrn1 = BatchNormalization(name='LRN_1')(pool1)
conv2 = Conv2D(filters=256, kernel_size=5, activation='relu', strides=1, padding='same', name='CONV_2')(lrn1)
pool2 = MaxPooling2D((3,3), strides=2, name='POOL_2')(conv2)
# lrn2 = local_response_normalization(conv2,depth_radius=5, bias=2, alpha=0.0001, beta=0.75)
lrn2 = BatchNormalization(name='LRN_2')(pool2)
conv3 = Conv2D(filters=384, kernel_size=3, activation='relu', strides=1, padding='same', name='CONV_3')(lrn2)
conv4 = Conv2D(filters=384, kernel_size=3, activation='relu', strides=1, padding='same', name='CONV_4')(conv3)
conv5 = Conv2D(filters=256, kernel_size=3, activation='relu', strides=1, padding='same', name='CONV_5')(conv4)
pool3 = MaxPooling2D((3,3), strides=2, name='POOL_3')(conv5)
# FC
f = Flatten()(pool3)
f = Dense(4096, activation='relu', name='FC_1')(f)
f = Dropout(0.5)(f) # 논문 parameter 0.5 이용
f = Dense(4096, activation='relu', name='FC_2')(f)
f = Dropout(0.5)(f)
out = Dense(1000, activation='softmax', name='OUTPUT')(f)
model = Model(inputs=x, outputs=out)
model.summary()
CIFAR10 data 적용
이제는 CIFAR10 data에 적용해보겠습니다. keras 내장 데이터를 이용하였습니다. 50000개와 10가지 종류의 라벨로 이루어진 내장데이터입니다. 10개의 라벨의 종류는 비행기, 자동차, 새, 고양이, 사슴, 개, 개구리, 말, 배, 트럭이 있습니다. 내장데이터의 픽셀은 224*224*3 대신 32*32*3이기 때문에, 위 아키텍처를 그대로 적용하기에는 파라미터가 너무 많아지는 이슈가 있었습니다. 따라서 약간의 모델 파라미터 수정 후 적용하였습니다. 자세한 code는 아래 colab 링크를 참고해주세요.
model.compile(loss='categorical_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=10,
verbose=1,
validation_data=(x_test, y_test))모델링 후 다음과 같이 학습한 결과 Test Acc 약 0.71정도를 얻었습니다. 너무 적은 데이터이고, overfitting이 유발된 듯 합니다.
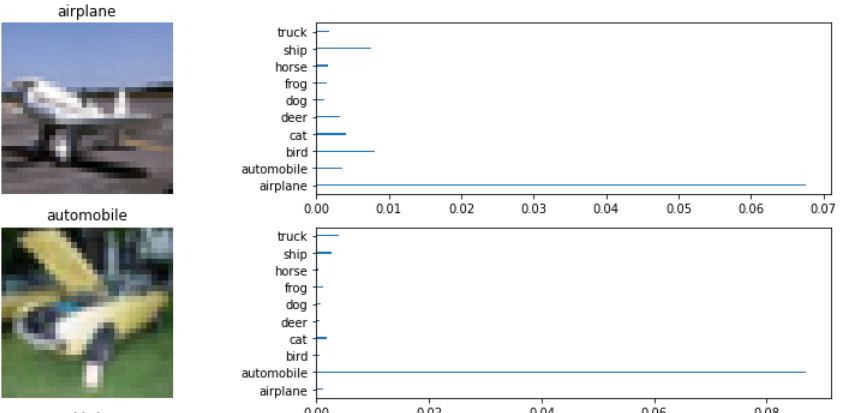
그래도 다음과 같이 논문에 나와있는 그래프를 그려보면, 꽤 잘 예측하고 있는 것을 확인할 수 있습니다. 자세한 code는 제 github 링크를 올려두겠습니다.
https://github.com/daeunni/Vision_models/blob/main/AlexNet(2012).ipynb
daeunni/Vision_models
CNN 기반 모델 codes 모음. Contribute to daeunni/Vision_models development by creating an account on GitHub.
github.com
'Computer Vision💖 > Basic' 카테고리의 다른 글
| [CV] Adversarial Learning(적대적 학습)이란? + 응용 (0) | 2022.04.24 |
|---|---|
| [CV] Self-supervised learning(자기주도학습)과 Contrastive learning - 스스로 학습하는 알고리즘 (4) | 2021.07.02 |
| [CV] AlexNet(2012)의 구조와 논문 리뷰 (0) | 2021.06.23 |
| [CV] ResNet - Residual Connection(잔차연결) (0) | 2021.05.04 |
| [STAT & DL] 딥러닝의 전반적 구조에 대한 통계적 해석 (0) | 2021.03.05 |