![[Robot] Point trajectory를 이용한 Policy Learning](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcThJHM%2FbtsQjPm5GIm%2FAAAAAAAAAAAAAAAAAAAAAFkFCBWIhC9xjRUKtJAL-8jvSjkvp0QAS66XVijRghYN%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3D6%252FH9d303Oaj9NlBKwUTBmigeHuk%253D)
반응형
[Sep 3 2025] Robot Learning: Mingyu's class
Any-point Trajectory Modeling for Policy Learning
https://arxiv.org/pdf/2401.00025
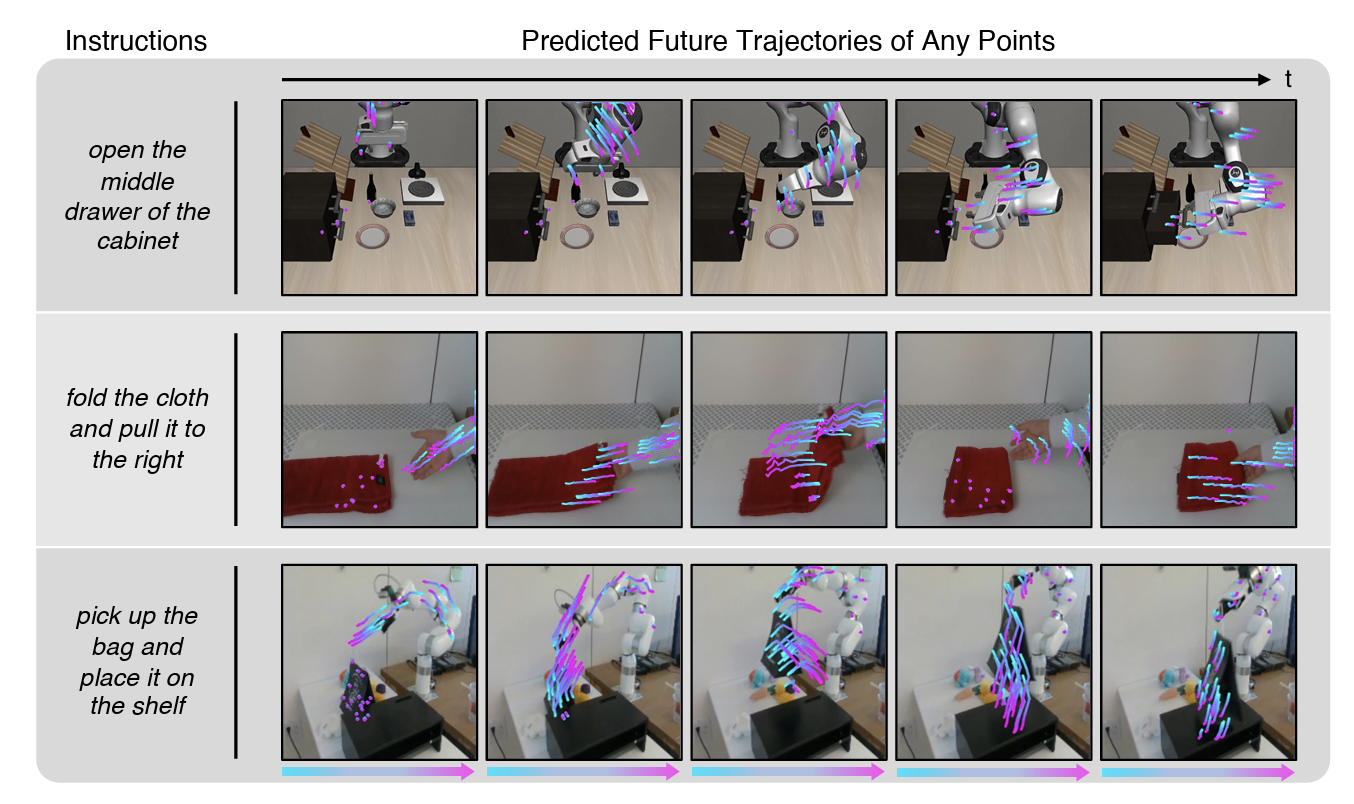
✅ 로봇 정책을 학습하려면 보통 action-labeled demonstration (상태+행동 짝 데이터)이 필요
- 예: 로봇이 컵을 잡는 영상을 보고 동시에 각 step에서 joint angle/action을 알아야 policy 학습이 가능
- 근데 이건 비용이 너무 큼: 수만 개 trajectory를 action까지 라벨링하는 데 몇 달~년 단위가 걸림
✅ Idea : Action 라벨 없는 비디오로도, 로봇이 쓸만한 representation을 뽑아내서 policy 학습을 돕자
- 임의의 point를 집어넣으면, 그 point가 앞으로 어디로 움직일지 trajectory를 예측하는 모델을 학습.
- 이 trajectory 예측 능력이 곧 세계의 동역학/물리 이해로 이어짐.
- 컵 위 점을 추적하면 → 컵이 앞으로 어디로 갈지 앎
- 손 위 점을 추적하면 → 손의 궤적을 예측 가능
- 이렇게 학습된 모델을 통해, 비디오만 보고도 “object-level 동작 예측”이 가능해짐.
- 컵 위에 점을 찍음
- 이 점이 앞으로 어디로 이동해야 할지를 trajectory로 예측함
- 예: 컵이 테이블에서 로봇 손 쪽으로 옮겨진다 → trajectory가 테이블에서 로봇 방향으로 움직임
- 로봇 policy는 “현재 비전 관찰 + 이 trajectory”를 입력으로 받아,
이 trajectory를 따라가도록 로봇의 action을 결정함.
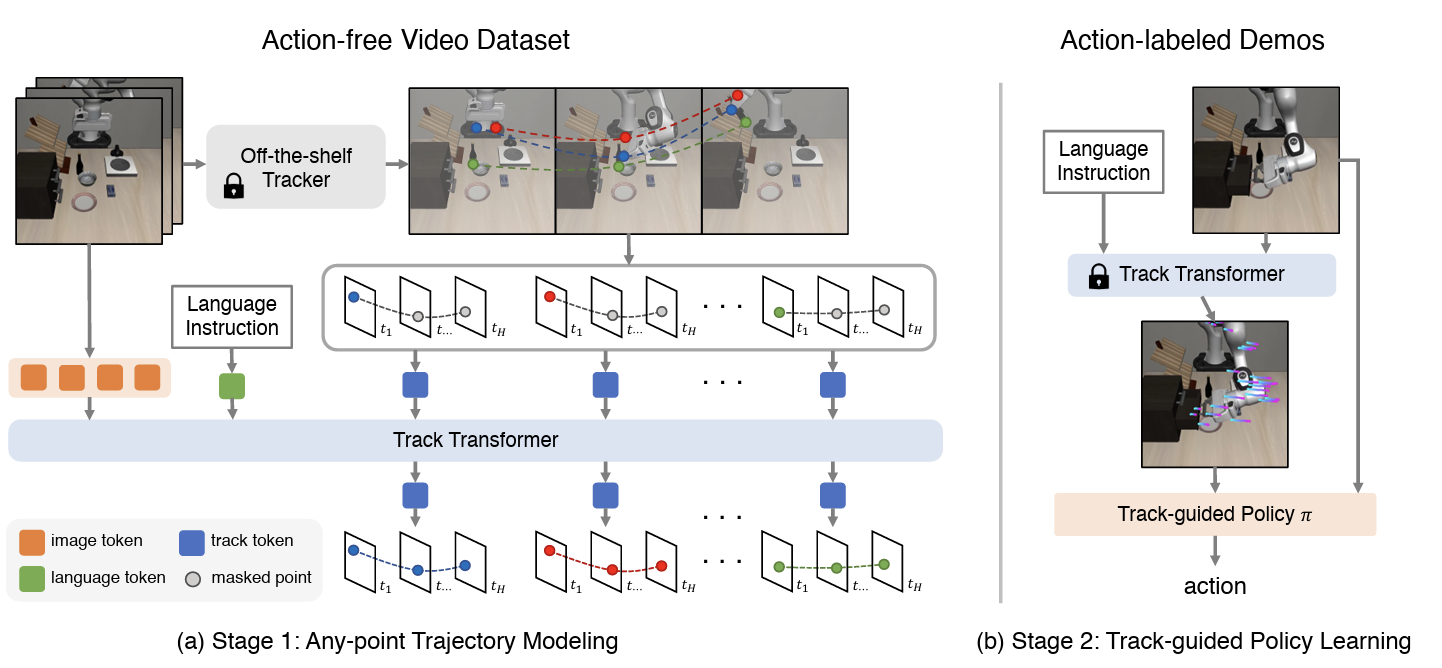
✅ 최종 Track Token 구성
- 위 세 가지 벡터를 합치거나(concatenation) 더한 뒤(linear fusion) 최종 임베딩을 얻음.
- 즉, track token은 **(좌표 위치 + 주변 시각 정보 + 시간 정보)**가 합쳐진 하나의 dense vector.
- (x, y) 좌표 → “이 포인트가 화면 어디에 있는지”
- 비주얼 특징 → “이 포인트가 어떤 물체/질감을 가진 영역인지”
- 시간 정보 → “이 포인트가 언제 등장한 것인지”
✅ Policy 학습 단계 (Stage 2)
- Pre-training Point Trajectory Prediction Model (Stage 1)
- 인터넷/휴먼/로봇 action-free 비디오에서 trajectory 예측 모델(Track Transformer)을 학습.
- 이때는 action 라벨 전혀 필요 없음.
- Policy learning (Stage 2)
- 이제 action-labeled demonstration은 아주 소량만 사용.
- 이때 policy network는:
- 입력: 현재 프레임 + (ATM이 예측한 미래 trajectory)
- 출력: 로봇의 action (예: end-effector 이동, gripper open/close 등)
- 즉, trajectory = sub-goal guidance 역할을 함.
- 예: “컵 위 점은 앞으로 여기까지 이동해야 한다 → 따라서 로봇 팔을 이렇게 움직여야 한다”
✅ 결과적으로 데모 수를 확 줄이고도 높은 성공률의 로봇 조작 정책을 학습 가능.
- 예: 기존 BC는 20% 데모 필요했는데, ATM은 4% 데모만 있어도 같은 성능.
반응형
'RL 🤖' 카테고리의 다른 글
| [Robot] GR-2를 보고 정리하는 OOD (Out-Of-Distribution) setting (0) | 2025.09.11 |
|---|---|
| [Robot] GR-1: Video generation을 robot manipulation에 활용하기 (1) | 2025.09.09 |
| [Daily] Unified Reward Model for Multimodal Understanding and Generation (0) | 2025.03.13 |