![[Robot] GR-1: Video generation을 robot manipulation에 활용하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbbR0h2%2FbtsQpH3wMVg%2FAAAAAAAAAAAAAAAAAAAAAAd8wRvHIQ1TJhkUG81V5CT418QrDjOny85RDTuWzBe6%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DsUhj5dBo0Bdd3u%252FRhWHKSGSNVP4%253D)
반응형
오늘 Mingyu 수업에서 재밌는 논문을 봤다. 역시 기록!
https://arxiv.org/pdf/2312.13139
✅ TL;DR
- 로봇을 사람 말대로 잘 움직이게 하려면, 그냥 행동 데이터만 학습시키는 게 아니라, 먼저 비디오를 대규모로 보면서 ‘앞으로 무슨 일이 일어날지’ 예측하는 능력을 길러주는 게 훨씬 좋다
- 로봇이 대규모 비디오 생성(pre-training)으로 “미래 화면을 예측하는 능력”을 먼저 배우게 하고, 그다음에 실제 로봇 조작 데이터로 조금만 fine-tuning 하면, 새로운 상황에서도 잘 적응하고 훨씬 성공률이 높아진다는 걸 증명
✅ Motivation
- 로봇 조작은 본질적으로 generative한 문제임 → 행동을 하면 환경이 변하고, 로봇은 그다음 시각 상태를 예측해야 함.
- 기존 방법들은 주로 discriminative mapping (지시문+이미지 → 행동)으로 접근, 즉 단순 매핑 문제로 다룸.
- 이 논문에서는 multi-task language-conditioned visual robot manipulation을 주장
- Video generation은 robot의 trajectory를 reasoning하기 위한 정말 밀접한 task임. 이를 통해 미래를 예측할 수 있다.
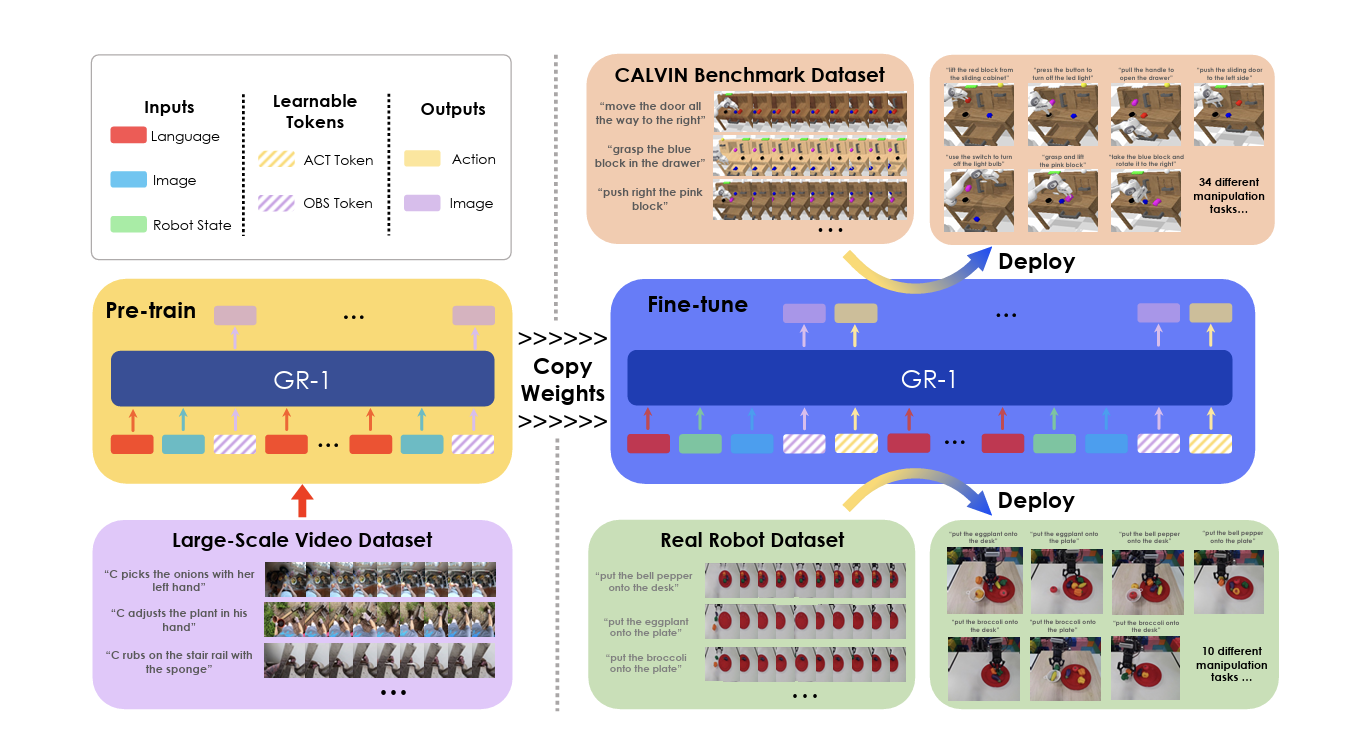
✅ Method
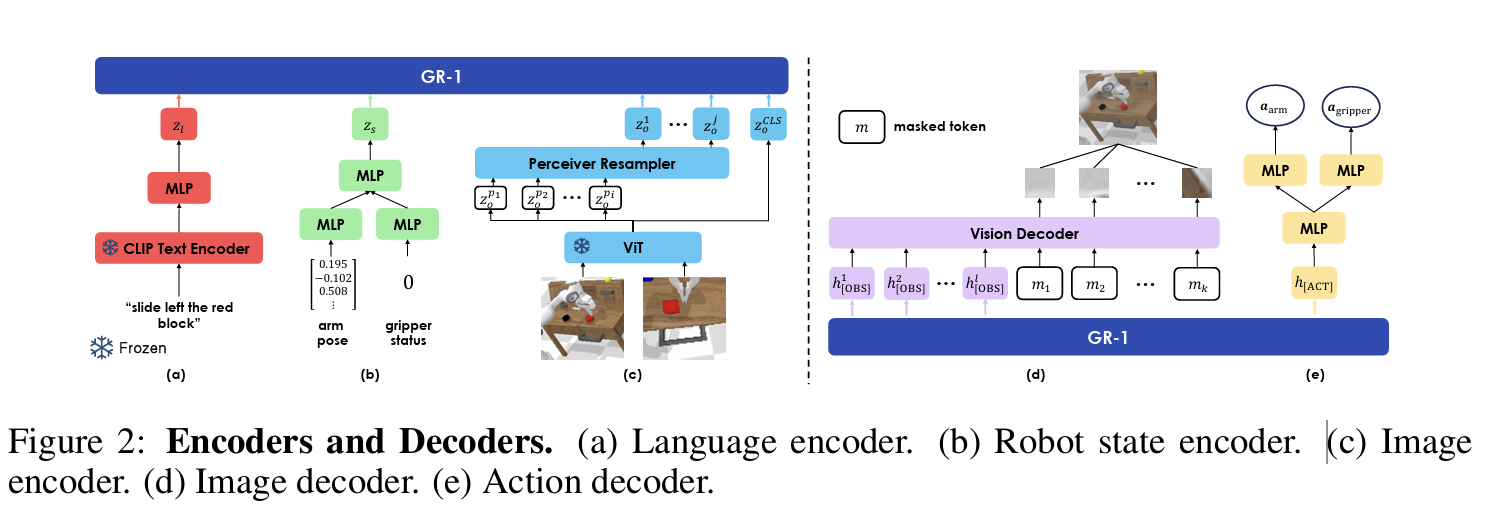
- GR-1 (Generative Robot Transformer 1)
- GPT 스타일 transformer 기반.
- Input (w/ encoding):
- Text instruction (text token from CLIP): “slide left the red block”
- Visual observation (patch token from ViT)
- Robot state input (proprioceptive embedding): robot의 현재 6D pose
-> Transformer에 넣기 전에 모든 embedding은 linear layer를 거침
- Output (w/ decoding):
- Future action (action tokens, 연속 제어값)
- Future video (future frame tokens, autoregressive하게 생성)
- Transformer의 [OBS] 출력과 mask tokens(학습 가능한 공유 임베딩 + 해당 패치의 positional encoding)을 Vision Decoder(self-attn + MLP)로 보냄.
- 각 mask token → 한 패치를 복원(= MAE 스타일 patch reconstruction).
- 한 타임스텝마다 “지금까지의 컨텍스트”를 보고 -> [ACT]는 다음 행동을, [OBS]는 다음(미래) 프레임을 각각 auto regressive로 예측하도록 함
- Training
- Pre-training: Ego4D로 미래 프레임 예측 학습.
- Fine-tuning: CALVIN 로봇 조작 데이터로 정책(action) 학습.
- Loss: Action prediction loss + Frame reconstruction loss.
- Frame prediction은 보조 학습 신호(regularizer)로 작동, action 학습을 안정화.
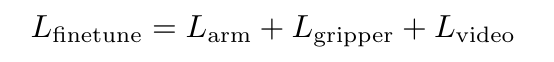
- Generated frames

✅ Experiment
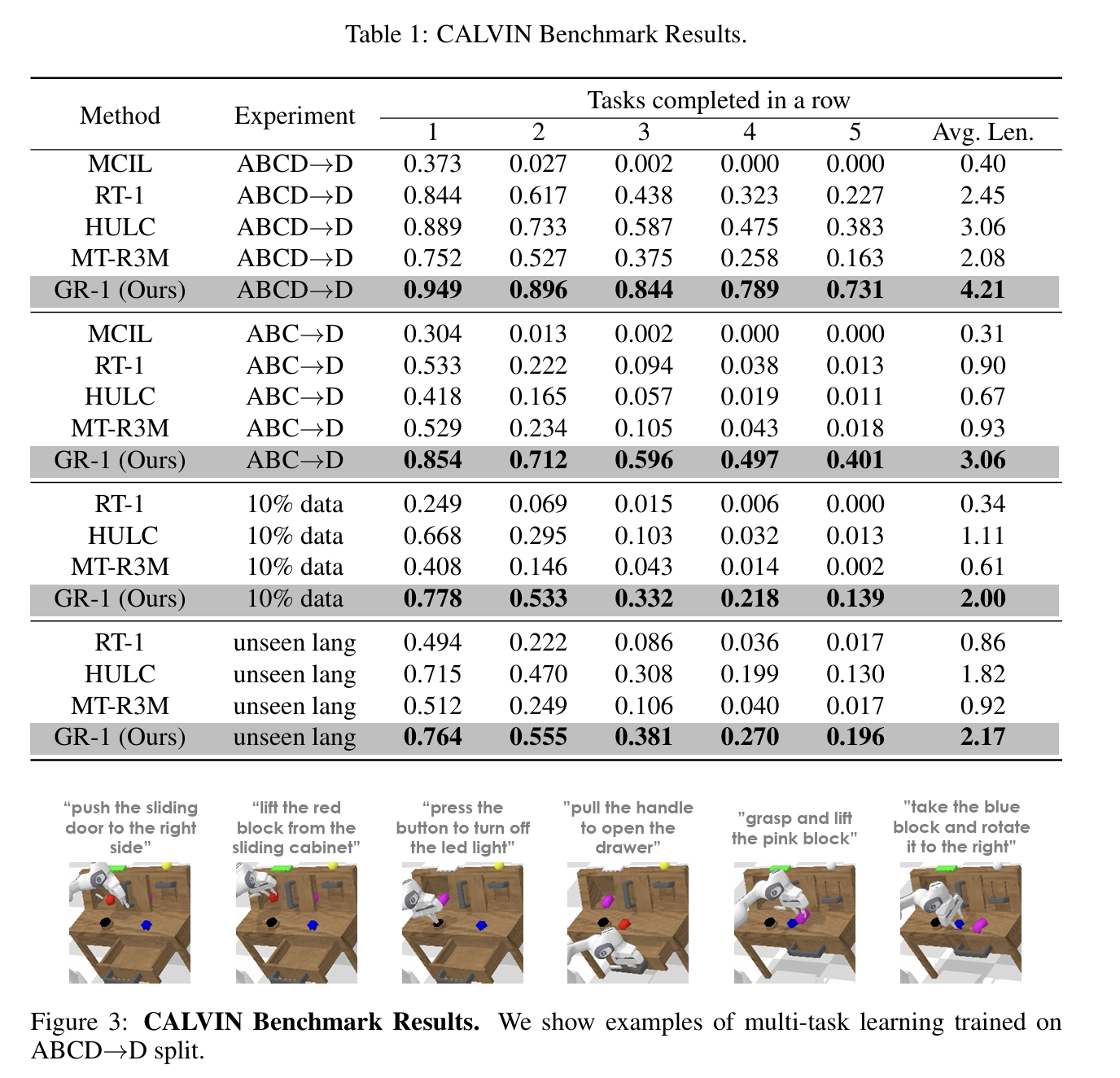
- Simulation (CALVIN benchmark)
- 지표: 성공률(Task Success), 연속 성공 과제 수(ASL), 데이터 효율성.
- 결과:
- 성공률: 88.9% → 94.9%
- 평균 연속 성공 과제 수: 3.06 → 4.21
- 데이터 10%만 사용 시에도 baseline보다 우수 (77.8% vs 66.8%).
- Zero-shot (Unseen scenes/objects)
- 새로운 방/객체에서도 테스트.
- 성공률: baseline 53.3% → GR-1 85.4%.
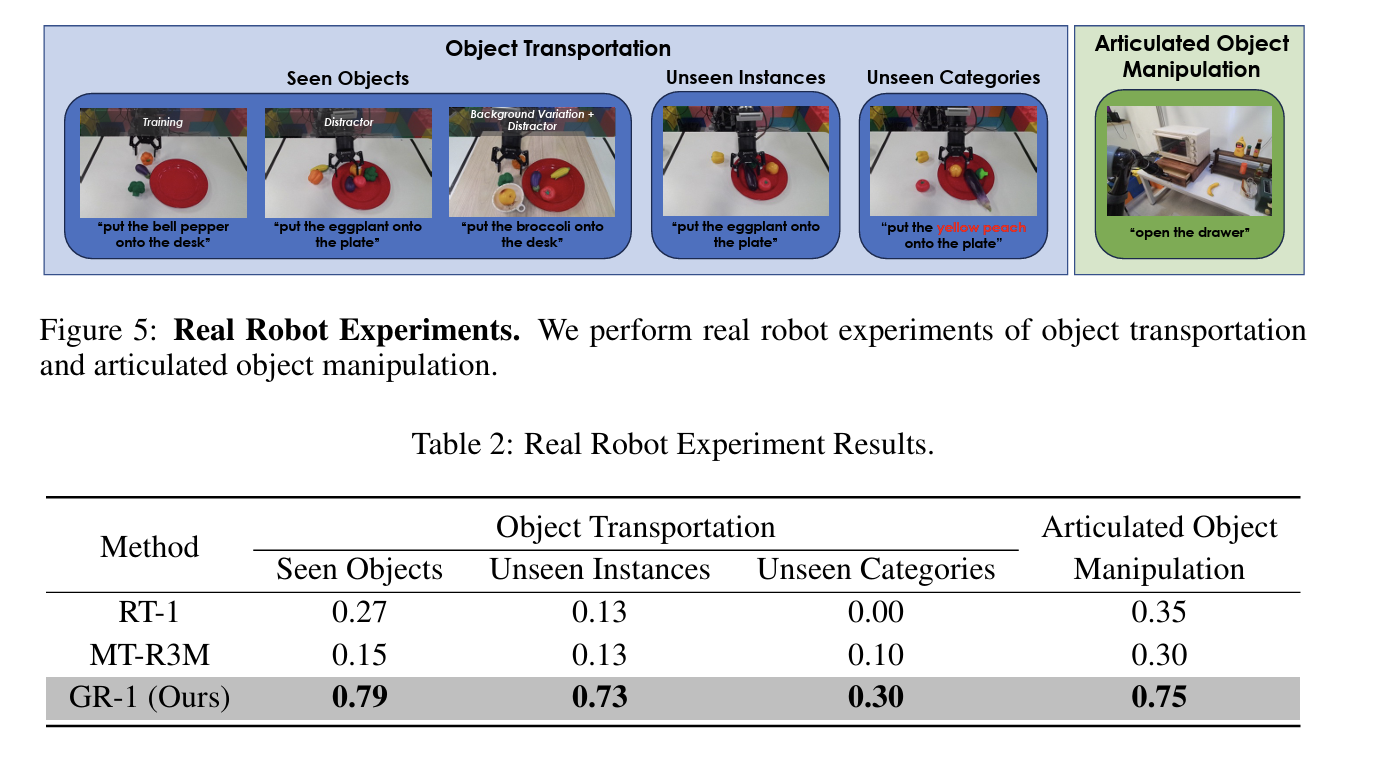
- Real robot (Real-world robot)
- 물리적 로봇 팔 환경에서 unseen scene/object 조작.
- 강력한 sim-to-real transfer 성능 입증.
반응형
'RL 🤖' 카테고리의 다른 글
| [Robot] GR-2를 보고 정리하는 OOD (Out-Of-Distribution) setting (0) | 2025.09.11 |
|---|---|
| [Robot] Point trajectory를 이용한 Policy Learning (0) | 2025.09.04 |
| [Daily] Unified Reward Model for Multimodal Understanding and Generation (0) | 2025.03.13 |