![[CV] AlexNet(2012)의 구조와 논문 리뷰](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fcf8LJr%2Fbtq7KlihdF7%2FAAAAAAAAAAAAAAAAAAAAALnTN2cwEDNhMMedv8u4o69Fs-X5K1fQB7POgHW83lp_%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DXH10jwpV1cbPvvezcBTCY%252BoB9%252Bc%253D)
오늘은 Deep한 CNN의 발전에 가장 큰 영향을 준 AlexNet(2012)에 대해 포스팅하고자 합니다.
AlexNet은 2012년에 개최된 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 에서 우승을 차지한 아키텍처로, 이전의 모델인 LeNet-5보다 더 Deep한 CNN 구조를 도입해 화제가 되었습니다. (여기서 LeNet-5은 정말 Simple한 초기 CNN 모델을 뜻합니다. 자세한 설명은 여기를 참고해주세요)
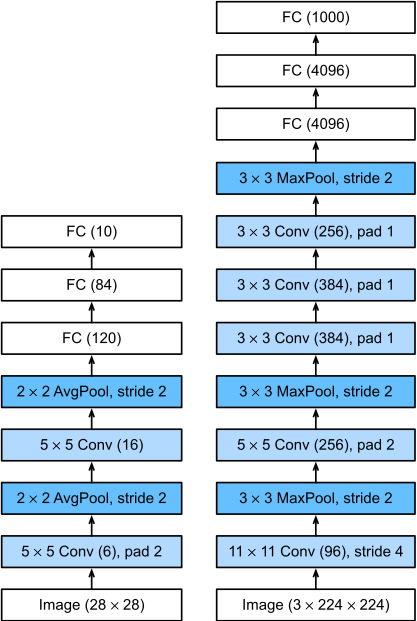
LeNet-5의 등장 이후, 대용량의 이미지 data를 다루기 위해서는 더 큰 학습 역량(a large learning capacity)을 가진 아키텍처가 필요했습니다. 다음 그림은 LeNet-5과 AlexNet의 아키텍처를 비교해 나타낸 그림인데요, 초기 CNN모델인 LeNet-5보다 훨씬 더 복잡하고 커진 모델임을 확인할 수 있습니다.
그리고 LeNet5과 달리 AlexNet은 GPU를 사용해 병렬 처리를 진행한 점이 특징인데요, 데이터를 2개의 GPU로 나누어 학습시키다가 하나의 layer에만 GPU 학습을 통합시키는 방식입니다. 다음 그림은 AlexNet을 이용해 각 GPU에서 학습된 필터맵을 나타낸 것입니다.

GPU 1에서는 비교적 색상과 관련 없는 정보를 학습하고, GPU2에서는 색상과 관련된 정보를 학습하고 있네요. 이렇게 2개의 GPU는 독립적으로 학습되고 있습니다.

논문에서 제시된 위 AlexNet의 아키텍처를 봐도, 두개의 GPU 사용을 고려해 두 갈래로 나누어 있는 것을 알 수 있습니다.
AlexNet의 기본 아키텍처
그럼 구체적으로 AlexNet의 아키텍처를 살펴보겠습니다. AlexNet은 기본적으로 5개의 Convolution층과 3개의 Fully-connected layer가 연결된 아키텍처로 구성되어있는데요, 활성화 함수는 ReLU, Pooling은 Maxpooling을 사용했습니다. (Pooling에 관해서는 여기를 참고해주시면 감사하겠습니다)
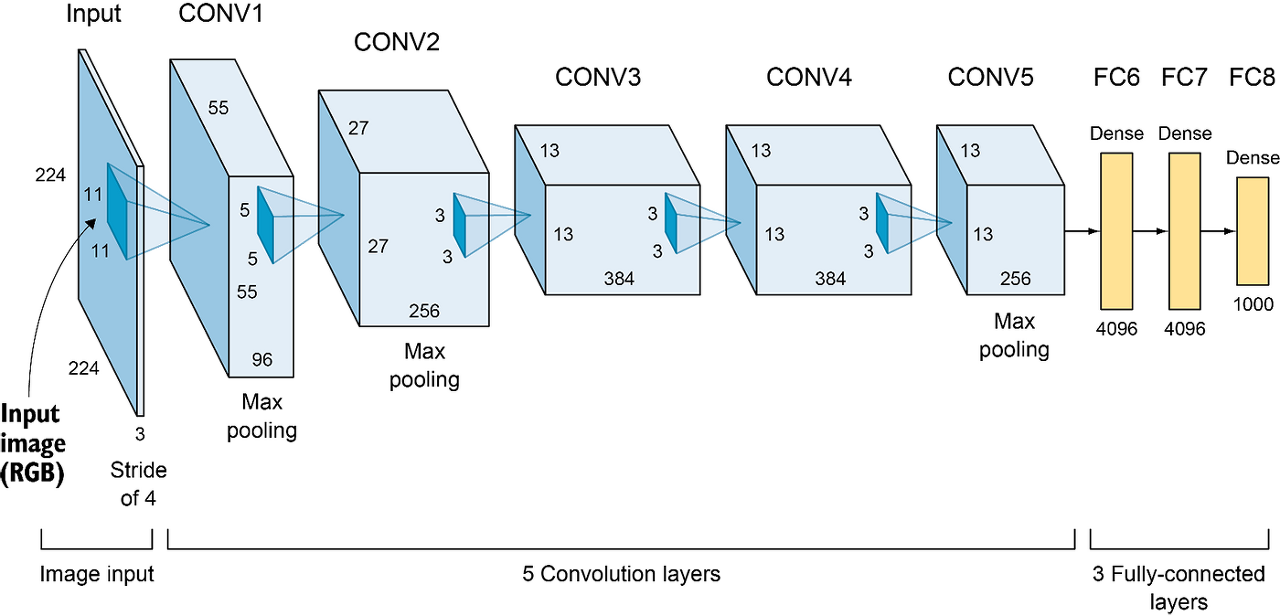
이러한 아키텍처에서는 학습을 돕기위한 여러 method로 구성되어 있는데요, 지금부터 논문에서 'novel', 'unusual' 하다고 칭했던 기법 중 3가지 method 들을 소개해드리고자 합니다.
1. ReLU의 사용
첫번째는 활성화함수로 ReLU를 사용했다는 것입니다. 이전까지는 tanh 함수를 사용했는데요, 이 두 함수에는 어떤 차이점이 있는걸까요? 우선 두 함수의 생김새는 다음과 같습니다.

우선 가장 차이점은 tanh함수는 [-1, 1] 범위에서 존재하지만, ReLU함수는 [0, ∞] 범위에 존재한다는 점입니다. 이러한 bounded 경계는 논문의 'Saturating(포화상태)' 개념과 관련있는데요, tanh 함수가 saturating function이기 때문에 non saturating한 ReLU보다 훨씬 느리다는 것이 논문의 주장입니다. 그럼 Saturating function이란 무엇인지 간단히 알아보겠습니다.

쉽게 생각하자면 -∞ 또는 +∞ 범위로 bounded되지 않고 발산하는 함수를 non-saturating 함수라고 정의하는 것입니다. ReLU함수는 +∞ 범위로 계속 무한대로 뻗어나가고 있기에 non-saturating 함수이고, 반면 tanh함수는 [-1, 1]로 bounded 되어있기 때문에 saturating 함수라는 것이죠. 이러한 saturating 함수의 완만한 기울기는 gradient의 update를 더디게 만든다고 알려져 있습니다. (기울기 미분값이 0이되기 때문에 gradient vanishing 등의 문제가 발생합니다.) 따라서 이는 느린 수렴의 원인이 됩니다. (자세한 설명은 여기를 참고해주세요)
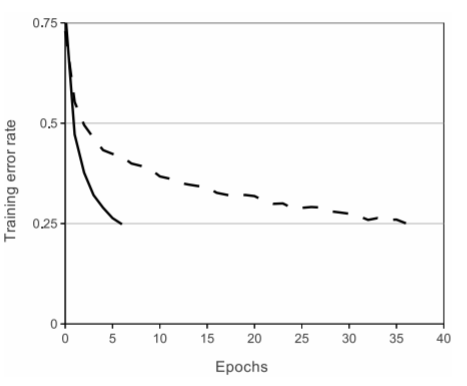
실제로 논문에서 제시한 위 그래프를 보시면, 실선인 ReLU 함수가 적은 epoch에도 빠른 train error rate 감소를 보이고 있는 것을 확인할 수 있습니다. 실제로 6배정도 더 빠른 성능을 보였다고 하네요. 따라서 본 고에서는 비포화함수인 ReLU를 채택합니다.
2. Local Responce Normalization(LRN) 의 사용
다음으로는 LRN이라고 불리는 기법의 사용입니다. 현재는 Batch normalization으로 잘 알려진 정규화 계열의 방법인데요, 이 방법은 인체의 현상 중 lateral inhibition(측면억제)에서 영감을 받아 만들어졌습니다. 우선 다음 그림을 보시죠.

위 그림을 보면 신기하게도 그냥 보면 흰색의 교차점 사이에 회색 점이 잘 보이지 않고, 검정색에 집중할 때 비로소 회색의 점이 보이는 것을 알 수 있습니다. 이는 '측면억제'의 대표적인 현상으로, 강한 자극인 검정색이 약한 자극인 회색의 인식을 막고있는 현상입니다. 결론적으로 이는 지역적(local)인 영향력이 반영된 인체의 현상인데요, LRN은 학습 과정에서 이러한 지역적인 현상을 약화하고, 좀 더 학습을 generalization(일반화) 하기 위해 고안되었습니다.
이제 서론은 뒤로하고, 본격적으로 LRN에 대해 알아보겠습니다. 사실 앞에서 언급한 Saturating함수(sigmoid, tanh 등)는 양 끝이 평평해지는 현상을 막기위해 normalization이 필요하다고 알려져있는데요, 근데 AlexNet은 앞서 말씀드린대로 ReLU를 사용했죠? ReLU는 non-saturating 함수로, 따라서 이러한 정규화가 특별히 요구되지 않습니다.
하지만 다른 단점이 있습니다. ReLU 함수의 생김새를 다시 볼까요?

ReLU 함수의 생김새를 보면, x가 0보다 큰 부분에서는 함수 값을 x로 그대로 유지하고 있음을 알 수 있습니다. 그렇다면 너무 큰 x 양수값이 들어와도, 이를 그대로 신경망에 전달하는 것인데 이는 앞선 예시에서 "검정색"(=강한 자극)의 역할을 하게 된다는 것이 LRN의 개요입니다. 본 고에서는 이러한 지역적인 현상을 예방하기 위하여 다음과 같은 식을 통해 Filter의 결과값을 정규화합니다.
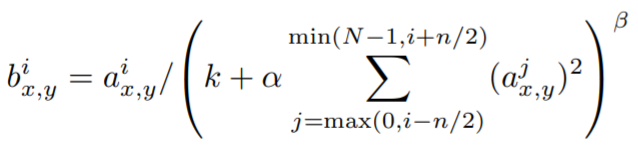

예를 들어 i=5, n=5라면, 현재 5번째 필터의 값을 정규화하는 process겠죠? n은 i번째 현재 필터의 값을 정규화 하는데 고려하는 지역적인 이웃한(adjacent) 필터값으로, 현재 5이기 때문에 5개의 이웃한 필터 값을 고려한다는 뜻이 됩니다. ( 여기서 n의 값은 정규화 영향력을 결정짓기 때문에 중요한 값이 되겠죠? )
이러한 5개의 이웃한 필터의 해당 (x, y) 포지션 값들을 모두 squared sum하면, 이 값이 클수록 LRN된 필터값은 원래 값보다 상대적으로 작아지고, 이 값이 작을수록 LRN된 필터값은 원래 값보다 상대적으로 커질 것입니다. 따라서 "강한 자극"은 약하게 만드는 것이죠.
하지만 현재는 이러한 LRN의 한계가 지적되어, Batch Normalization으로 정규화를 진행하고 있습니다. 이에 대한 설명은 후에 포스팅하도록 하겠습니다.
3. Overlapping Pooling의 사용
마지막으로 본 고에서는 Pooling을 'Overlap(중첩)' 하여 사용한 것이 특징인데요, 그럼 기존의 pooling 방법과는 어떤 것이 차이가 있는 걸까요? 이 분 블로그에 잘 정리된 그림이 있어서 가져왔습니다. 다음 그림을 보시죠.

기존에는 위 그림의 상단처럼 Overlap 하지 않은 pooling을 사용했습니다. 하지만 본 고에서는 stride를 조절하여 Overlappling pooling을 사용했습니다. 본 고에서는 이는 기존의 방법보다 약간 더 overfitting의 해결에 효과적이라는 점을 error rates를 통해 제시합니다. 사실 지금은 흔히 사용되는 pooling 방법이죠.
Overfitting 해결을 위해
그럼 지금까지 AlexNet의 기본 아키텍쳐와, 아키텍쳐 안에 중점적으로 사용된 method 3개를 알아봤습니다. 하지만 눈치채신 분들도 계시겠지만, LeNet-5보다 깊어진 레이어는 훨씬 더 많은 모수(6천만개)가 필요했습니다. 모수가 많으면 Overfitting의 영향 또한 무시할 수 없는데요, 따라서 본 고에서는 overfitting을 해결하기 위해 다음과 같은 2가지 방법을 사용했습니다. 첫번째는 Augmentation이고, 두번째는 Dropout입니다.
Data Augmentation (데이터 증대)
Augmentation은 CNN 모델에서 데이터를 다양하게 증대시키는 방법인데요, 본 고에서는 두가지 방법을 사용합니다. 첫번째는 단순 '수평반전'을 하는 것이고, 두번째는 PCA를 이용해 RGB 픽셀 값을 변화시키는 것입니다.
Horizaontal reflection
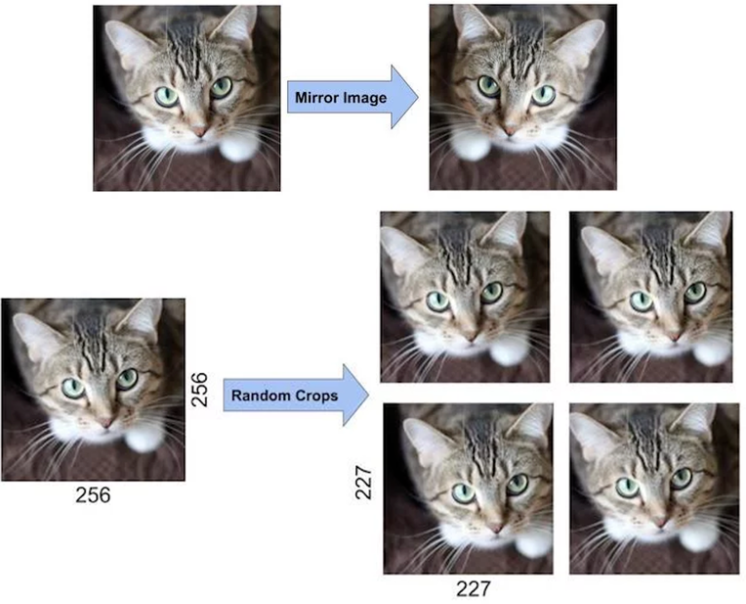
쉽게 말해서 한 이미지를 수평으로 뒤집고, 이를 random 하게 crop해서 이미지를 증대시키는 방법입니다. 이렇게 전환한다면 조금 더 많은 학습 이미지를 형성하고 다양한 학습이 가능해질 수 있겠죠?
Dropout
다음은 유명한 방법인 dropout 입니다.
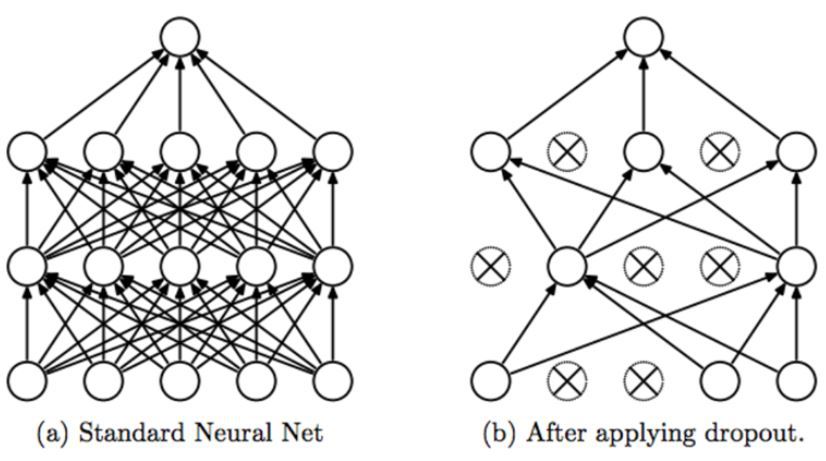
Dropout이란 단순 Dense 노드 값을 0으로 바꾸어, 그 노드의 영향력을 제거하는 기법을 뜻합니다. 사실 여러가지 모델의 예측값을 Combine 하는 것은 test error를 줄이는 가장 좋은 방법일 수 있습니다. 일종의 앙상블의 효과를 낼 수 있는 것이죠. 하지만 이는 too-expensive 한 방법이겠죠? 따라서 이러한 '앙상블'의 효과를 낼 수 있는 것이 Dropout입니다. 왜냐하면 서로 다른 노드를 random으로 drop한다면, 같은 아키텍쳐라도 다른 노드가 포함된 서로 다른 모델이 될 수 있으니까요. 따라서 본 고에서는 이러한 dropout 방법을 채택합니다.
지금까지 AlexNet의 논문 리뷰와 기본적인 아키텍처 등을 알아보았습니다. 다음 포스팅에서는 이러한 아키텍처를 code로 하나하나 구현해보도록 하겠습니다! 읽어주셔서 감사합니다 :)
References
[0] https://bskyvision.com/421
[1] https://deep-learning-study.tistory.com/376
[2] https://developpaper.com/attention-mechanism-relu-activation-function-adaptive-parameterized-relu-activation-function/
[3] https://colab.research.google.com/github/d2l-ai/d2l-tensorflow-colab/blob/master/chapter_convolutional-modern/alexnet.ipynb
[4] https://stats.stackexchange.com/questions/174295/what-does-the-term-saturating-nonlinearities-mean
[5] https://www.quora.com/Why-would-a-saturated-neuron-be-a-problem
'Computer Vision💖 > Basic' 카테고리의 다른 글
| [CV] Adversarial Learning(적대적 학습)이란? + 응용 (0) | 2022.04.24 |
|---|---|
| [CV] Self-supervised learning(자기주도학습)과 Contrastive learning - 스스로 학습하는 알고리즘 (4) | 2021.07.02 |
| [CV] AlexNet(2012) 논문을 code로 구현 해보자 (Keras, PyTorch) (0) | 2021.06.25 |
| [CV] ResNet - Residual Connection(잔차연결) (0) | 2021.05.04 |
| [STAT & DL] 딥러닝의 전반적 구조에 대한 통계적 해석 (0) | 2021.03.05 |